2024-01-17 15:26:52
1月17日,商湯科技與上海AI實驗室聯(lián)合香港中文大學(xué)和復(fù)旦大學(xué)正式發(fā)布新一代大語言模型書?·浦語2.0(InternLM2)。InternLM2的核心理念在于回歸語言建模的本質(zhì),致力于通過提高語料質(zhì)量及信息密度,實現(xiàn)模型基座語言建模能力質(zhì)的提升,進(jìn)而在數(shù)理、代碼、對話、創(chuàng)作等各方面都取得長足進(jìn)步,綜合性能達(dá)到開源模型的領(lǐng)先水平。
InternLM2是在2.6萬億token的高質(zhì)量語料上訓(xùn)練得到的。沿襲第一代書生·浦語(InternLM)的設(shè)定,InternLM2包含7B及20B兩種參數(shù)規(guī)格及基座、對話等版本,滿足不同復(fù)雜應(yīng)用場景需求,繼續(xù)開源,提供免費商用授權(quán)。

開源鏈接
Github:https://github.com/InternLM/InternLM
HuggingFace:https://huggingface.co/internlm
ModelScope:https://modelscope.cn/organization/Shanghai_AI_Laboratory
大模型的研究應(yīng)回歸語言建模本質(zhì),大模型各項性能提升的基礎(chǔ)在于語言建模能力的增強(qiáng)。為此,聯(lián)合團(tuán)隊提出了新一代的數(shù)據(jù)清洗過濾技術(shù),通過更高質(zhì)量的語料以及更高的信息密度,筑牢大模型能力基礎(chǔ)。
主要發(fā)展了以下幾個方面的技術(shù)方法:
多維度數(shù)據(jù)價值評估:基于文本質(zhì)量、信息質(zhì)量、信息密度等維度對數(shù)據(jù)價值進(jìn)行綜合評估與提升;
高質(zhì)量語料驅(qū)動的數(shù)據(jù)富集:利用高質(zhì)量語料的特征從物理世界、互聯(lián)網(wǎng)以及語料庫中進(jìn)一步富集類似語料;
針對性的數(shù)據(jù)補齊:針對性補充語料,重點加強(qiáng)現(xiàn)實世界知識、數(shù)理、代碼等核心能力。
目前,浦語背后的數(shù)據(jù)清洗過濾技術(shù)已經(jīng)歷三輪迭代升級。僅使用約60%的訓(xùn)練數(shù)據(jù)即可達(dá)到使用第二代數(shù)據(jù)訓(xùn)練1T tokens的性能表現(xiàn),模型訓(xùn)練效率大幅提升。
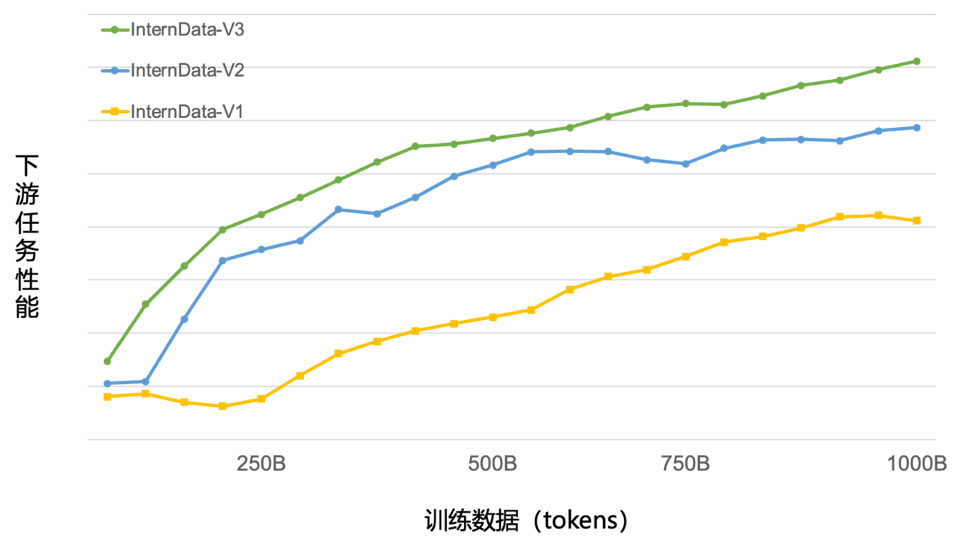
第三代數(shù)據(jù)清洗過濾技術(shù)大幅度提升模型訓(xùn)練效率
基于第三代數(shù)據(jù)清洗過濾技術(shù),InternLM2語言建模能力實現(xiàn)了顯著增強(qiáng)。

與第一代InternLM相比,InternLM2在大規(guī)模高質(zhì)量的驗證語料上的Loss分布整體左移,表明其語言建模能力實質(zhì)性增強(qiáng)
長語境輸入及理解能力能夠顯著拓展大模型應(yīng)用場景,比如支持大型文檔處理、復(fù)雜的推理演算和實際場景的工具調(diào)用等。然而,大模型有限的上下文長度當(dāng)前仍是學(xué)界及業(yè)內(nèi)面臨的重要難題。通過拓展訓(xùn)練窗口大小和位置編碼改進(jìn),InternLM2支持20萬tokens的上下文,能夠一次性接受并處理約30萬漢字(約五六百頁的文檔)的輸入內(nèi)容,準(zhǔn)確提取關(guān)鍵信息,實現(xiàn)長文本中“大海撈針”。
參考業(yè)界范例,研究人員對InternLM2進(jìn)行了“大海撈針”試驗:將關(guān)鍵信息隨機(jī)插入一段長文本的不同位置并設(shè)置問題,測試模型能否從中提取出關(guān)鍵信息。
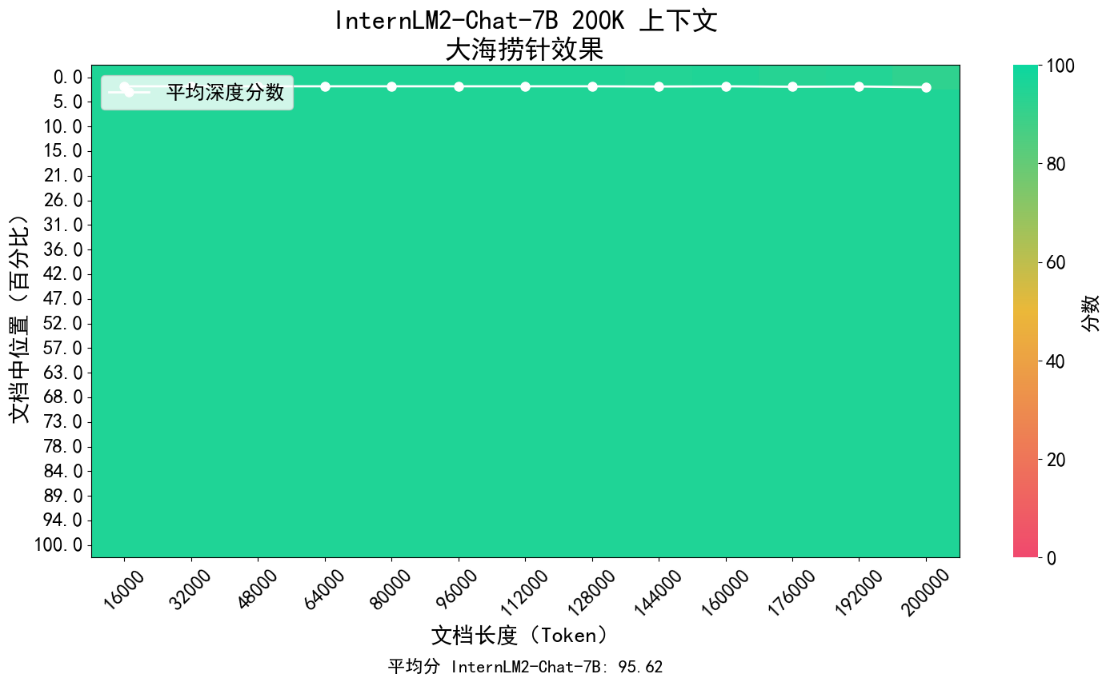
InternLM2“大海撈針”試驗效果
上圖展示了InternLM2在不同長度的上下文(橫軸)及上下文中不同位置(縱軸)上召回關(guān)鍵信息的準(zhǔn)確率(Recall)。紅色代表較低的召回準(zhǔn)確率,而綠色則代表較高的召回率。試驗結(jié)果表明,InternLM2在上下文長度延展到200K時依舊保持了近乎完美的召回成功率,驗證了InternLM2對于超長上下文堅實的支持能力。
為測試InternLM2在真實長文本處理任務(wù)中的能力,研究人員將一份時長3小時的公開會議錄音轉(zhuǎn)錄稿輸入模型中,并要求InternLM2從中提取出關(guān)鍵信息。測試結(jié)果表明,盡管在未校對的文本中存在較多錯別字,但I(xiàn)nternLM2仍從中準(zhǔn)確提煉出了關(guān)鍵信息,并總結(jié)了關(guān)鍵發(fā)言人的觀點。
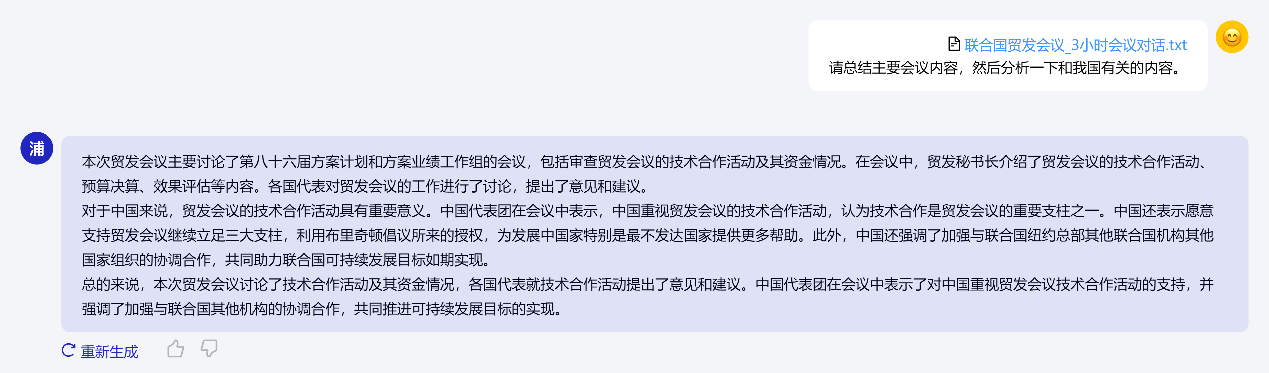
InternLM2準(zhǔn)確總結(jié)“聯(lián)合國2023年10月2日召開的聯(lián)合國貿(mào)易和發(fā)展會議會議記錄”
InternLM2的各項能力取得全面進(jìn)步,相比于初代InternLM,在推理、數(shù)學(xué)、代碼等方面的能力提升尤為顯著,綜合能力領(lǐng)先于同量級開源模型。
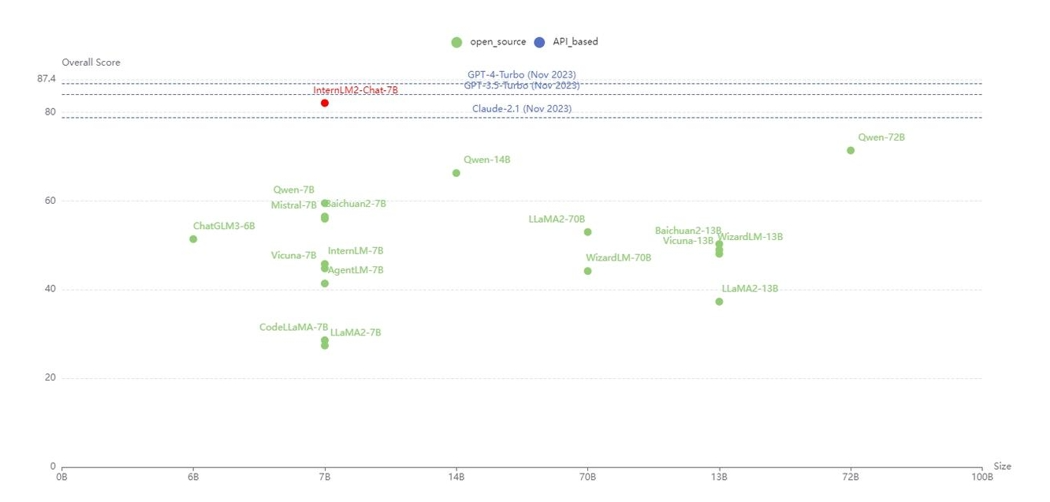
根據(jù)大語言模型的應(yīng)用方式和用戶關(guān)注的重點領(lǐng)域,研究人員定義了語言、知識、推理、數(shù)學(xué)、代碼、考試六個能力維度,在55個主流評測集上對多個同量級模型的表現(xiàn)進(jìn)行了綜合評測。評測結(jié)果顯示,InternLM2的輕量級及中量級版本性能在同量級模型中表現(xiàn)優(yōu)異。
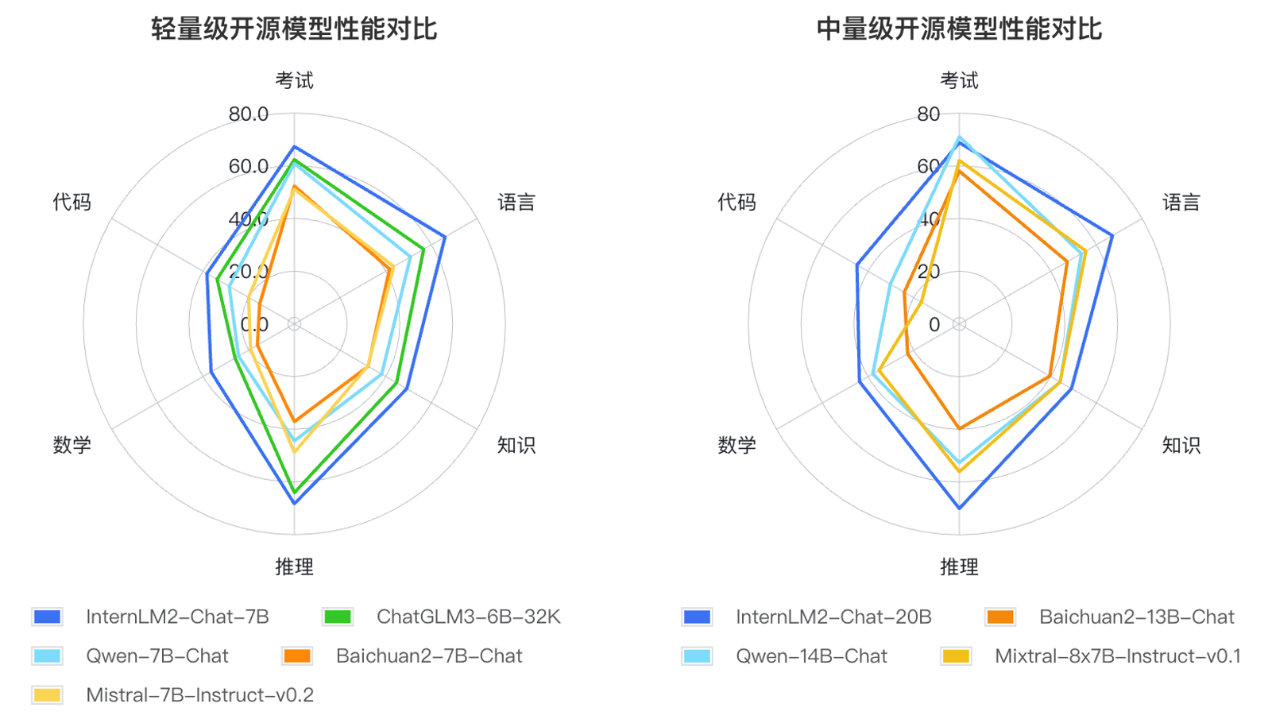
InternLM2的輕量級及中量級版本性能在同量級開源模型中表現(xiàn)優(yōu)異
下面的表格對比了InternLM2各版本與ChatGPT(GPT-3.5)以及GPT-4在典型評測集上的表現(xiàn)。可以看到,InternLM2只用20B參數(shù)的中等規(guī)模,即在整體表現(xiàn)上達(dá)到了與ChatGPT比肩的水平。其中,在AGIEval、BigBench-Hard(BBH)、GSM8K、MATH等對推理能力有較高要求的評測上,InternLM2表現(xiàn)甚至優(yōu)于ChatGPT。
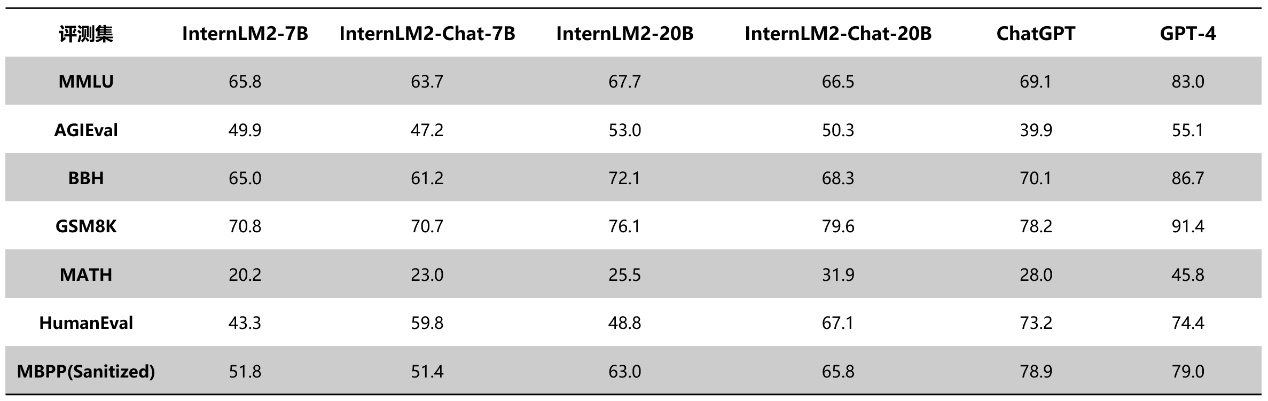
InternLM2與ChatGPT的評測結(jié)果對比
與此同時,綜合性能的增強(qiáng),帶來了下游任務(wù)的全方位能力提升。新發(fā)布的InternLM2提供優(yōu)秀的對話及創(chuàng)作體驗,支持多輪任務(wù)規(guī)劃及工具調(diào)用,并提供實用的數(shù)據(jù)分析能力。
InternLM2不僅在客觀性能指標(biāo)上提升顯著,在主觀體驗上也有明顯改善,可以為用戶提供優(yōu)秀的對話和交互體驗。研究測試表明,InternLM2-Chat可以精準(zhǔn)地理解和遵循用戶意圖,具備較強(qiáng)的共情能力和豐富的結(jié)構(gòu)化創(chuàng)作能力。下面展示幾個示例:
示例一:在嚴(yán)格的格式要求下編制課程大綱

InternLM2設(shè)計的課程大綱精準(zhǔn)遵循用戶要求(比如格式、數(shù)量、內(nèi)容等)。
示例二:以富有人文關(guān)懷的回答開解用戶

InternLM2能夠在對話中與用戶“共情”
示例三:展開想象力,編寫《流浪地球3》的劇本

InternLM2設(shè)計的具備充滿豐富的合理想象,比如外星遺跡、量子糾纏的引入等。同時整個故事表現(xiàn)了人類面對危機(jī)時的勇氣和團(tuán)結(jié)精神。
對話和創(chuàng)造的體驗進(jìn)步的原因,一方面是基礎(chǔ)語言能力的顯著增強(qiáng),另一方面也得益于微調(diào)技術(shù)的提升。InternLM2進(jìn)行微調(diào)的過程使用了經(jīng)過第三代數(shù)據(jù)清洗過濾技術(shù)處理的指令微調(diào)語料,同時也采用了更強(qiáng)的Online RLHF。研究人員在微調(diào)InternLM2的過程中,對獎勵模型和對話模型進(jìn)行了三輪迭代更新,每一輪更新均針對前一輪模型的表現(xiàn)更新偏好數(shù)據(jù)與提示詞。在獎勵模型訓(xùn)練(RM)和近端策略優(yōu)化(PPO)階段,研究人員均衡采用各類提示詞,不僅提高了對話的安全性,也提升了用戶體驗。
基于更強(qiáng)大、更具泛化性的指令理解、工具篩選與結(jié)果反思等能力,InternLM2可支持復(fù)雜智能體的搭建,支持對工具進(jìn)行多輪有效調(diào)用及多步驟規(guī)劃,完成復(fù)雜任務(wù)。聯(lián)合團(tuán)隊針對多種任務(wù)構(gòu)建了細(xì)粒度工具調(diào)用評測集T-Eval(https://open-compass.github.io/T-Eval),InternLM2-Chat-7B在該評測集上表現(xiàn)超越了Claude-2.1和目前的開源模型,性能接近GPT-3.5。
InternLM2工具調(diào)用能力全面提升
通過工具調(diào)用,使得大語言模型可通過搜索、計算、代碼解釋器等獲取知識并處理更復(fù)雜的問題,從而拓展應(yīng)用邊界。研究人員對模型調(diào)用工具流程實施細(xì)粒度的拆解和分析,針對規(guī)劃、推理、工具選擇、理解、執(zhí)行、反思等步驟進(jìn)行了針對性增強(qiáng)和優(yōu)化。

基于InternLM2通過開源智能體框架Lagent搭建的用戶助手智能體,能夠在一次指令回應(yīng)中完成地圖查詢、路線規(guī)劃、發(fā)郵件等任務(wù)
數(shù)學(xué)能力是大模型邏輯思維和推理能力的重要體現(xiàn)。上海AI實驗室對InternLM2的數(shù)學(xué)能力進(jìn)行全面提升,使其達(dá)到當(dāng)前開源模型的標(biāo)桿水平。
基于更加科學(xué)構(gòu)建的預(yù)訓(xùn)練語料,InternLM2形成了很強(qiáng)的內(nèi)生計算能力。在不依靠計算器等外部工具的情況下,在100以內(nèi)的簡單數(shù)學(xué)運算上能夠做到接近100%的準(zhǔn)確率,在1000以內(nèi)達(dá)到80%左右的運算準(zhǔn)確率。在GSM8K和MATH評測中,InternLM2-20B的表現(xiàn)超過了ChatGPT(GPT-3.5)。

InternLM2在100以內(nèi)的簡單數(shù)學(xué)運算上能夠做到接近100%的準(zhǔn)確率
為應(yīng)對各類復(fù)雜計算,InternLM2-Chat還可借助代碼解釋器(Code-Interpreter)編寫代碼進(jìn)行計算,或?qū)ν评淼慕Y(jié)果進(jìn)行形式化驗證,從而解決計算要求更高或者演算過程更加復(fù)雜的問題。在典型的數(shù)學(xué)評測集GSM8K和MATH上,配合代碼解釋器,InternLM2取得了更高的評測分?jǐn)?shù)。其中對于難度更高的MATH數(shù)據(jù)集,InternLM2的計算精度從32.5大幅提升到51.2,甚至超過了GPT-4的表現(xiàn)。

InternLM2與ChatGPT的數(shù)學(xué)能力評測結(jié)果對比
下面的示例展示了InternLM2可以和代碼解釋器結(jié)合解決較復(fù)雜的高等數(shù)學(xué)問題。
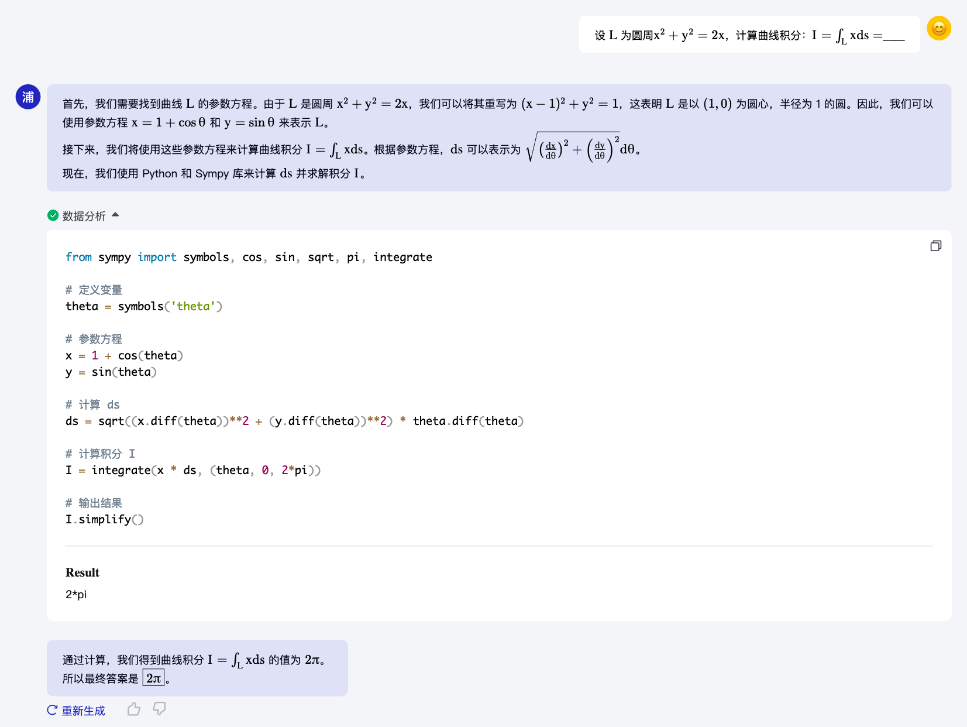
InternLM2能夠完成積分求解等高等數(shù)學(xué)題目
基于在計算及工具調(diào)用方面強(qiáng)大的基礎(chǔ)能力,InternLM2在語言模型中具備了數(shù)據(jù)分析和可視化實用能力,進(jìn)一步貼近用戶使用場景。
向InternLM2輸入國家統(tǒng)計局公布的“2023年3-11月份規(guī)模以上工業(yè)企業(yè)主要財務(wù)指標(biāo)(分行業(yè))”,InternLM2能夠分析數(shù)據(jù)并繪制折線圖
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2024 每日經(jīng)濟(jì)新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












