每日經濟新聞 2024-05-17 16:34:12
◎ 截至5月16日,國內發布的305個大模型中約有六成尚未成功備案。一名大模型行業創業者告訴每經記者,沒備案的大模型也不代表就消失在市面上。對于大模型的商業化,有行業人士認為,當下和未來兩三年,大模型的商業探索會在成本和Token質量上相互妥協,并逐漸分化為兩派。
每經記者 可楊 楊卉 每經編輯 蘭素英
【編者按】:
本周,OpenAI推出新一代旗艦AI模型——GPT-4o。而早在2023年3月15日,GPT-4就已正式問世,其強大的文本生成能力迅速使生成式AI成為全球焦點,掀起了一場AI技術競賽的浪潮。
在國內,生成式大模型的發布同樣風起云涌。2023年3月16日,百度發布“文心一言”大模型;2023年4月10日,商湯科技的日日新發布;2023年4月11日,阿里巴巴的通義千問發布;2023年7月7日,華為云推出盤古大模型3.0……各方力量爭先恐后,爭奇斗艷,這股熱潮被形象地稱為“百模大戰”。
那么,一年多過去了,國內大模型企業的發展現狀如何?硅谷的生態又有怎樣的新變化?在這一領域中,科技巨頭和初創企業展現出了怎樣的發展方向?對此,《每日經濟新聞》特推出《“百模大戰”周年考》策劃,深入探討這些問題。
一年前的3月15日,隨著OpenAI多模態預訓練大模型GPT-4的發布,國內包括百度、華為、騰訊等科技巨頭,百川智能等初創企業,以及智譜AI研究院等研究機構紛紛揚帆起航,投身到人工智能(AI)大模型開發,試圖搭上這趟時代的列車,轟轟烈烈的“百模大戰”也由此開啟。
據《每日經濟新聞》記者的不完全統計,截至今年4月底,國內共計推出了305個大模型。而截至5月16日,只有約140個大模型完成生成式人工智能服務備案,占發布總量的45.9%。這意味著,還有約165個大模型尚未獲得“過審”機會。
這一嚴峻現實的背后除了有技術層面的難度,還有訓練和推理過程中高昂算力成本的制約;即便是跨過這一關,大模型企業如何實現商業化,依然著面臨不小的難度。而對這場競賽中可能被“出局”的公司來說,未來的路又在何方呢?
GPT-4的發布在全球掀起了“煉大模型”的熱潮,面對這一新藍海,科技巨頭、初創企業以及科研院校相繼開啟布局,沒人想錯過這趟時代的列車。
據《每日經濟新聞》不完全統計,截至今年4月底,國內共推出了約305個大模型,在過去一年推動著語言理解、圖像識別等多個領域的技術進步。
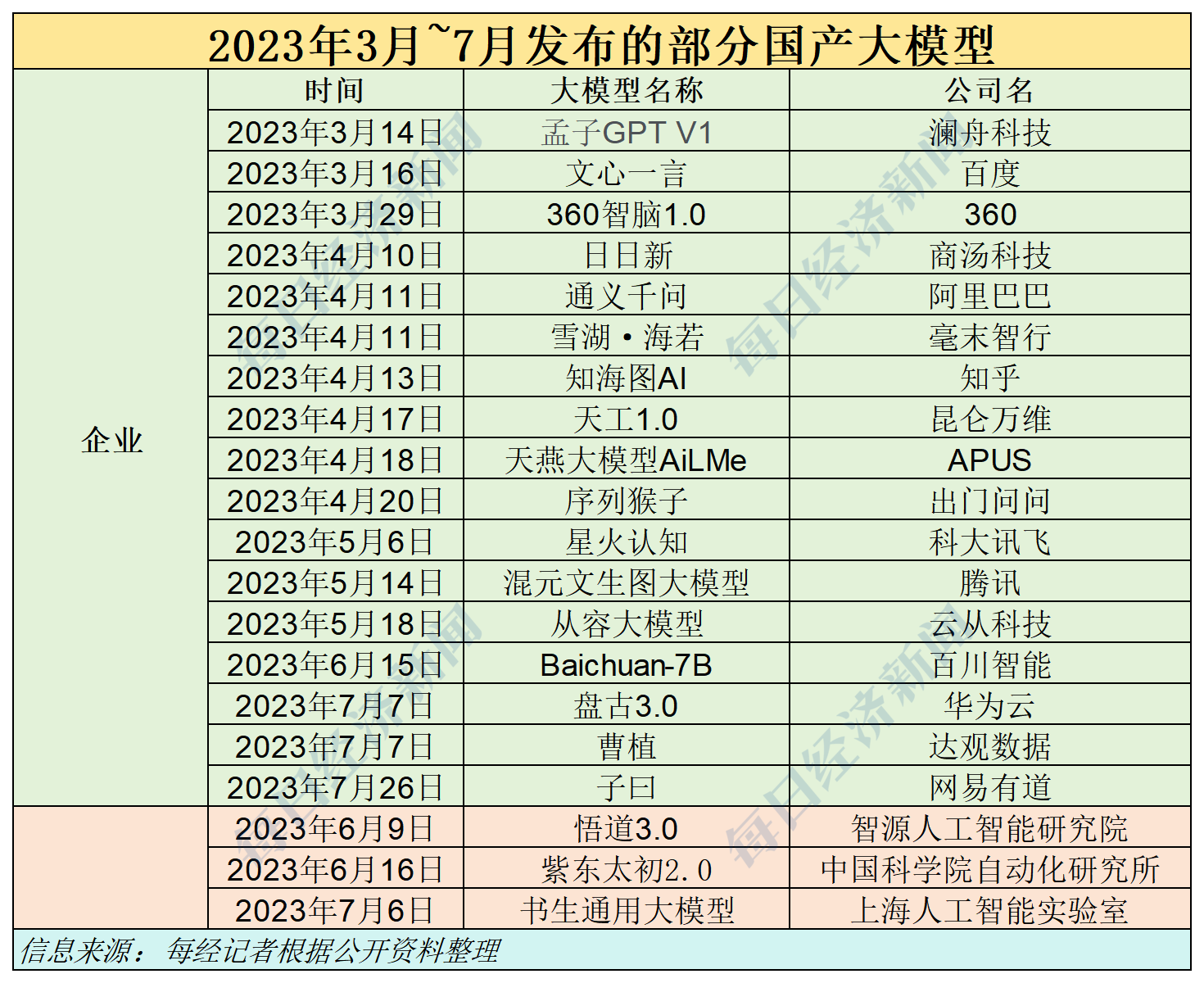
截至2024年5月16日,國內共有約140個大模型完成生成式人工智能服務備案,占305個大模型的45.9%左右。
此前,國家網信辦有關負責人就《辦法》相關問題回答媒體提問時介紹,《辦法》規定,利用生成式人工智能技術向中華人民共和國境內公眾提供生成文本、圖片、音頻、視頻等內容的服務,適用本辦法。
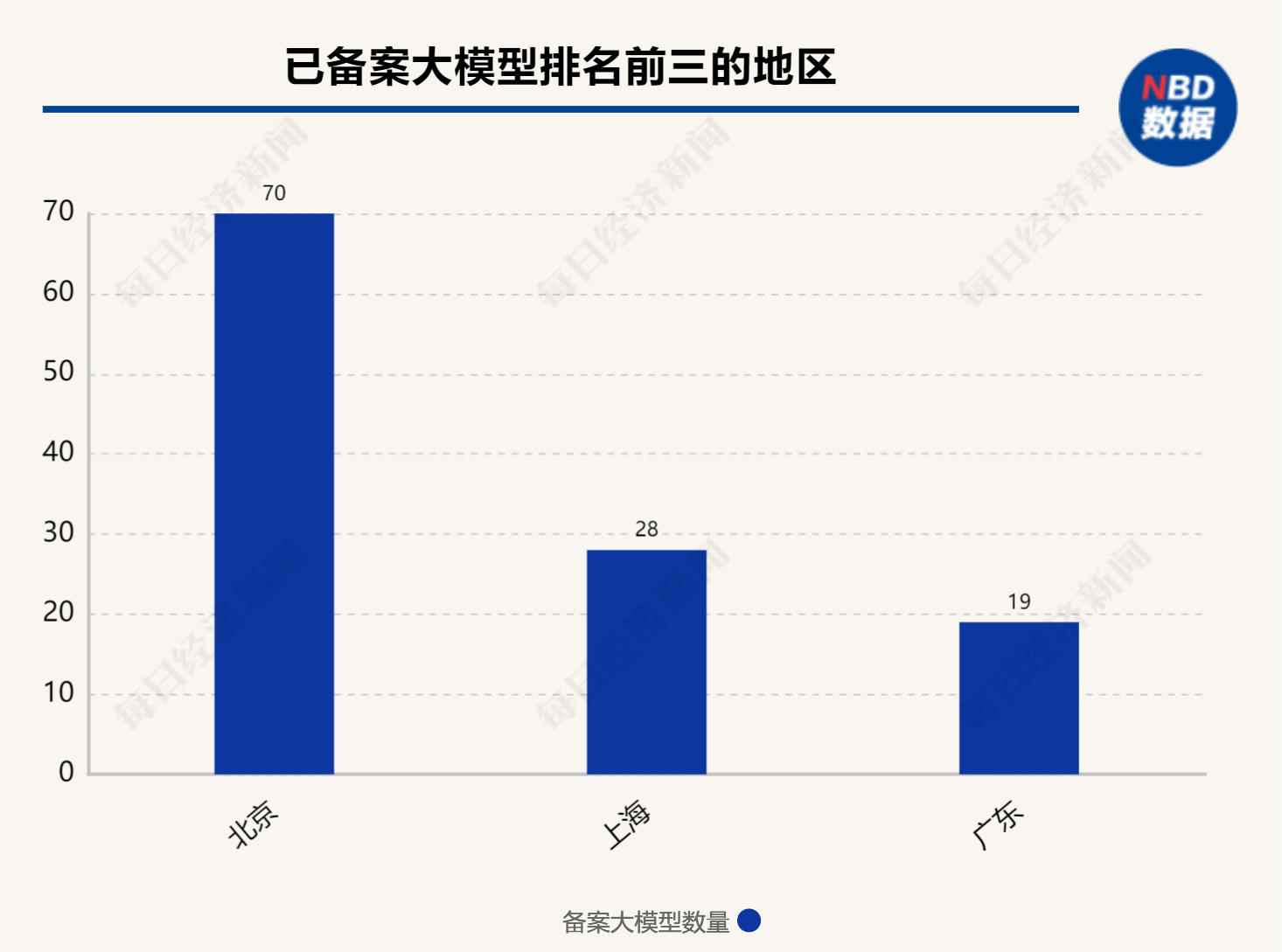
在已備案的大模型中,在地域分布上,北京以70個備案大模型領跑全國,凸顯了其在AI領域的集聚效應。上海和廣東緊隨其后,分別有28個和19個模型備案。
而“140”這一數字同時也意味著,從備案層面來看,大約還有165個大模型依舊未通過備案,無法公開向公眾提供服務。這些尚未能“過審”的大模型中,不乏一些備受關注的明星項目,包括曾號稱是“國內首個ChatGPT”的元語智能大模型ChatYuan。
更多未完成備案的是“學院派”大模型。在305個大模型中,有60個大模型是由大學或研究院所研發。或許是由于研究機構的項目更偏重學術探索,而非商業應用,備案動力或流程可能不如企業迅速。也有大模型轉向“境內深度合成服務算法”備案,例如恒生電子的大模型。
一名大模型行業創業者對《每日經濟新聞》記者介紹稱,當前模型相關的備案申請有點像專利申請,并不一定會通過,且申請周期較長,約在4~6個月。他表示,當下,大模型只要做To C服務,就需要備案,而在B端,一些大客戶會要求大模型公司完成備案工作。
不過他同時強調,沒備案的大模型也不代表就消失在市面上,很多來自研究所、大學的大模型僅僅只用于研究,就沒有動機去完成備案。
一家大模型頭部企業從業人士也告訴記者,來自大學的大模型,如果只做自己學術范圍內的研究,是可以不用備案的。
“百模大戰”行至此時,最終留下3~5家大模型已經成為行業對于這場競賽最終結局的共識。“大模型這個行業(到最后)可能就不存在了,未來大模型就是幾個最基本的底座,只有少數的幾家公司。”行行AI董事長、順福資本創始人李明順曾在接受《每日經濟新聞》記者采訪時坦言。
算力資源的稀缺性是制約大模型發展的關鍵瓶頸。對不少大模型來說,沒能挺過一周年,難搞的算力要負很大責任。對于模型廠商而言,目前主要的算力成本包括預訓練成本和推理成本。模型推理應用階段對算力的需求要遠遠高于訓練階段。
據中國工程院院士鄭緯民計算,在大模型訓練的過程中,70%的開銷要花在算力上;推理過程中95%的花費也是在算力上。
以GPT-4為例,該模型的訓練需要一萬塊英偉達A100芯片跑上11個月。假設每塊A100的成本為10000美元(價格因供應商和購買數量而異),那么一萬塊A100的總成本約為1億美元。
對于許多急匆匆踏上大模型賽道的創業公司或科技企業來說,在“燒”了一陣子錢后,他們絕望地發現,算力不僅越來越貴,質量也開始下降。
鄭緯民表示,目前,市面上只有三類系統可支持大模型訓練。其中,基于英偉達GPU的系統一卡難求;基于國產AI芯片的系統面臨國產卡應用不足、生態系統有待改善的問題;而基于超級計算機的系統,雖然可在作好軟硬件協同設計的情況下實現大模型訓練,但需在超算機器尚未飽和的前提下操作,私人企業獲得超算設備的機會并不大。
據英特爾方面介紹,在大模型領域,去年關注點更多是在模型訓練上,對成本和功耗并不那么重視,彼時,企業都希望能訓練一個自己的通用大模型。隨著很多通用大模型被訓練出來,今年關注的重點則轉移到了推理。對企業來說,大模型訓練出來是需要變現且能夠盈利的。但目前市場上很多大模型都是基于開源的,性能差不多,用于訓練的數據也差不多,很難通過差異化來盈利。
沒有足夠的資金支撐推理過程,成了很多創業者敗退的原因之一。為了降低成本,部分企業正在嘗試探索是否可以用CPU來做大模型推理。從當前一些案例來看,在130億參數以下的大模型中,CPU是可以做到的這一點的。
然而,即便是熬過了推理關,企業要將大模型變現仍有不小的難度。在行云集成電路創始人季宇看來,大模型的商業落地與早期互聯網時代相比區別很大,邊際成本仍然非常高。大模型每增加一個用戶,基礎設施需增加的成本是肉眼可見的,一個月幾十美元的訂閱費用根本不足以抵消背后高昂的成本。
更為關鍵的是,眼下大模型要大規模商業化,在模型質量、上下文長度等方面還有進一步訴求,不排除會進一步增加邊際成本。目前來看,日活千萬的通用大模型一年需超過100億元的收入才能支撐其背后的數據中心成本,未來大模型要像互聯網產業一樣服務上億人,成本一定是邁不過去的檻。
如果說“百模大戰”最后的贏家只屬于少數幾家公司,那在這場賽事中被淘汰的公司,未來會走向何方?
昆侖萬維董事長方漢曾在接受《每日經濟新聞》記者采訪時表示,“百模大戰”會淘汰一部分公司,剩下的科技公司肯定會繼續全速前進。
在行云集成電路創始人季宇看來,當下和未來兩三年,大模型的商業探索會在成本和Token質量上相互妥協,并逐漸分化為兩派。
一派是質量優先,用高端系統打造高質量的通用大模型,尋找超級應用來覆蓋高昂的成本。另一派是成本優先,用足夠便宜的硬件提供基本夠用的Token質量,尋找垂直場景的落地。若能在同樣的成本下買到規格大得多的芯片,跑一個百億千億模型,支持超長上下文,商業化的空間會比今天大得多,就像曾經的顯卡和游戲行業一樣。
啟明創投合伙人周志峰認為,當下,絕大多數的大模型企業是包著大模型的皮,裹著應用的心,“擁有模型能力的團隊更容易在算法、模型、數據、模型的加速方面去做優化,以達到體驗更好的產品,尤其對比那些用第三方模型純粹做應用的公司。這一類公司其實不是模型公司,未來一定會是一家應用公司”。
周志峰以字節跳動為例,從今日頭條到抖音到TikTok,背后的軸是AI驅動的推薦引擎。“字節跳動第一輪、第二輪融資的時候跟我們投資人講得更多的故事是AI驅動的推進引擎,而今天不會再去說字節跳動是一家AI技術公司,只會記得是哪幾個應用造成了這么大的規模。”同理,今天大部分的大模型公司未來也一定是靠它最終闖出了超級應用,大家因為這個超級應用而記住這家公司。
李明順也持同樣的觀點,即不遠的未來,有一部分大模型公司要轉型成應用公司,因為大模型領域不需要這么多公司,“有一些大模型公司的創始人有Plan A和Plan B的雙計劃,就是一旦我的模型實在是拼不過前面的5家之后,就要被迫在一些垂直領域里面找到生存之地,它就會轉型為一家應用公司。”
在備案成功的大模型中,部分模型已經從通用型轉變為聚焦特定領域或行業的細分垂類模型。
中科聞歌董事長王磊在接受《每日經濟新聞》記者采訪時坦言,在過去的半年到一年內,適當做小行業大模型,降低參數規模的趨勢已經變得非常明顯。真正成功的商業應用不是制造一個巨無霸,而是能夠被用戶廣泛使用且價格適中。“實用至上是關鍵,不必為了面子而去追求大規模,高昂的代價會影響產品的市場推廣和用戶的使用,實用性才是商業發展的主導原則。”
王磊表示,目前國內企業都意識到,最受歡迎的規模是70億和130億,300億是單臺推理的參數規模,比較受歡迎。“在我們的大模型發布時,國外網友評價這是企業級應用的小型參數規格。我認為一般的企業可能難以承受更大規模的產品。對于文本生成任務,這個規模基本上是足夠的,但對于一些特定領域的任務,還需要強化模型的能力。”
第四范式也同樣堅定選擇投入行業大模型。“如果說無限把模型做大,往里面放無限多的數據,最后可能會達到AGI的狀態,但是在每一個垂直應用,我們都要平衡好能力以及代價”。創始人戴文淵此前在第四范式的業績溝通會上也表示,從技術的角度來說,第四范式也追求AGI,但是與此同時,“對于每一個客戶的具體場景,我們也要做一定的裁剪,比如說這個考試只考數學,不一定需要讓它有物理的能力。”
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













