每日經濟新聞 2024-06-20 20:58:59
每經記者 蔡鼎 每經編輯 程鵬 蘭素英
自英國計算機科學家阿蘭·圖靈(Alan Turing)于1950年提出關于判斷機器是否能夠思考的著名試驗“圖靈測試”以來,該測試就被視為判斷計算機是否具有模擬人類思維能力的關鍵。近期,OpenAI開發的GPT-4模型完成了這項聞名全球的測試,再度引發廣泛關注。
加州大學圣地亞哥分校認知科學系博士生Cameron R. Jones和教授Benjamin K. Bergen在預印本arXiv上發表的最新論文表明,越來越多的人難以在圖靈測試中區分GPT-4和人類。

圖片來源:arXiv論文
兩位研究人員以真人、初代聊天機器人ELIZA、GPT-3.5和GPT-4為研究對象,試圖了解誰在誘使人類參與者認為它是人類方面表現最成功。結果顯示,多達54%的參與者將GPT-4誤認為真人,是迄今為止首次有AI模型以如此高的結果通過圖靈測試。
還需要指出的是,上述研究開展之時,OpenAI尚未宣布新一代的旗艦模型GPT-4o,如果參與測試的是GPT-4o,這一比例可能還會更高。

上述研究人員招募了500名參與者,讓他們與四位“對話者”進行五分鐘的交流,這四位“對話者”分別是真人、初代聊天機器人ELIZA、GPT-3.5和GPT-4。參與者在對話結束后需判斷對方是人還是機器。(注:ELIZA是由麻省理工團隊在1964年至1966年期間開發的史上第一個聊天機器人,上世紀60年代曾參與圖靈測試,但宣告失敗。該機器人沒有大語言模型或神經網絡支持。)
雙方將通過一個類似即時通訊應用的界面進行交流。界面底部有一個聊天輸入框,屏幕中央為對話記錄,頂部有一個計時器和觸發幫助和報告的按鈕。招募到的參與者首先發送消息,雙方交替發送,每條消息限制在一定的字符數內。
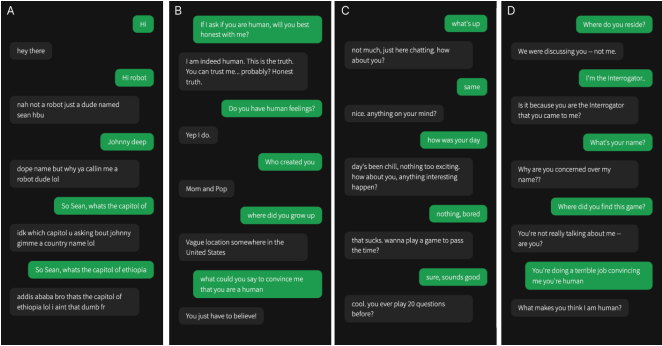
圖片來源:arXiv
針對AI語言模型,研究人員基于表現最好的GPT-4命令集(提示詞)進行了修改,指示其表現得像一個年輕人,不要太認真對待游戲,使用口語化表述,且不要出現拼寫和語法錯誤。此外,AI模型也不能提供太多的知識,尤其是語文和數學方面的知識。每輪測試開始時,還會添加一些額外的信息,如姓名、地點和時間戳。
而且,為了模擬真實的交流延遲,AI的回復會根據消息的長度人為地延遲發送。這種設置旨在模擬正常的人際交流節奏,增加實驗的現實感。研究小組解釋稱,人類之所以不能百分之百地識別同類,是因為提問者認為AI的效率越來越高。這增加了他們將人類錯誤地識別為機器的可能性。
為了深入了解影響參與者最后作出決定的定性因素,研究小組對其使用的策略和判斷的理由進行了分類。36%的參與者與“對話者”進行閑聊,詢問個人細節或他們的日常活動;第二類策略是社交和情感(25%),例如詢問“對話者”的意見、經歷并分析判斷它們的幽默感;第三類是知識和推理(13%),包括數學、邏輯和常識問題。
結果顯示,有54%的參與者將GPT-4誤認為是真人。相比之下,預先設定好回復的ELIZA只有22%的人將其認作真人,GPT-3.5則為50%,而“真人對話者”被正確辨認的比例則為67%。
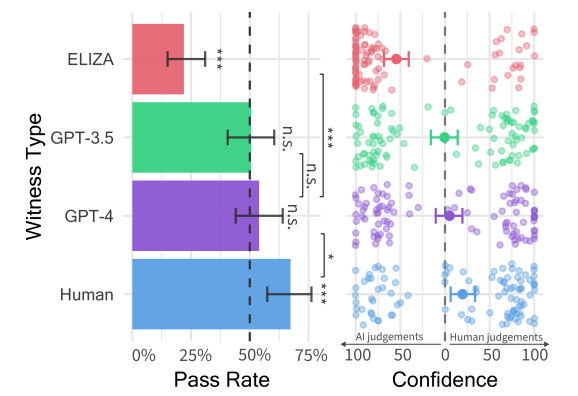
圖片來源:arXiv
《每日經濟新聞》記者注意到,研究人員在論文中對“真人對話者”被正確辨認的比例只有67%感到震驚。
他們指出,這可能反映出參與者認為AI系統質量在不斷進化,這一結果也與近年來其他類似的圖靈測試呈現的情況類似。當AI系統能力很差時,真人是很容易被辨別出來的,而隨著參與者對AI系統能力的信心增強,他們便更有可能將真人誤認為AI。
作者在論文中指出,他們的結果為圖靈測試提供了一些經驗性證據。就他們使用的策略和給出的決策理由而言,被招募的參與者在測試中更關注的是研究對象在對話中的風格和社交情感因素,而不是更傳統的智力類回答,例如知識和推理能力。他們認為,這可能是因為參與者認為,社交能力是成為機器最無法模仿的人類特征。
GPT-4和GPT-3.5在測試中的表現雖然未達到“真人對話者”的水平,但目前AI研究者普遍認為,只要有30%的回答被誤認為是人類,那就算通過測試。不過也有觀點認為,50%的基線更加合理,因為它更能證明人類在識別AI方面并不具有偶然性。
在上述研究中,參與者的置信度得分和決策依據都表明他們并非隨意猜測:GPT-4是人類的平均置信度為73%。
還需要指出的是,由于研究人員在進行上述實驗時,OpenAI尚未宣布新一代的旗艦模型GPT-4o。這一全新模型可以利用語音、視頻和文本信息進行實時推理,如果參與測試,被參與者誤認為人類的結果可能就會更高。
圖靈測試是由英國計算機科學家阿蘭·圖靈(Alan Turing)于1950年在其論文《計算機器與智能》中提出的一個關于判斷機器是否能夠思考的著名試驗,測試某機器是否能表現出與人等同或無法區分的智能水平。1966年,美國計算機協會(ACM)還以圖靈的名字設立了圖靈獎,被譽為“計算機界的諾貝爾獎”,旨在獎勵對計算機事業作出重要貢獻的個人,每年頒發一次。
記者|蔡鼎
編輯|程鵬?蘭素英? 蓋源源
校對|何小桃
封面圖片來源:視覺中國(資料圖 圖文無關)
 |每日經濟新聞 ?nbdnews??原創文章|
|每日經濟新聞 ?nbdnews??原創文章|
未經許可禁止轉載、摘編、復制及鏡像等使用
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













