每日經濟新聞 2024-06-25 16:21:53

生成式AI大模型正在深刻改變媒體行業,為內容創作與傳播帶來了革命性的變化。
那么,面對“百模大戰”,面對市面上數量眾多的大模型,媒體行業工作者或內容創作者,究竟該如何選擇大模型?在內容創作的特定場景選擇哪個大模型?
面對上述困惑,近期,由30余位每日經濟新聞優秀記者、編輯和子公司每經科技工程師組建的 “每日經濟新聞大模型評測小組”,對市場上主流大模型在財經新聞工作場景中的表現與能力進行了歷時2個月深入評測,并推出《每日經濟新聞大模型評測報告》(第一期)。
《每日經濟新聞大模型評測報告》(第一期)顯示,國產大模型正在全面趕超海外大模型,零一萬物 Yi-Large成為最大“黑馬”,在“財經新聞標題創作”“微博新聞寫作”“文章差錯校對”“財務數據計算與分析”四大應用場景的總分排名第一。幻方求索DeepSeek-V2、百川智能Baichuan4則在“財務數據計算與分析”場景顯示出強大的數據計算和分析能力。而一直備受各界推崇的GPT 4.0在本次評測中表現不佳,甚至在“財經新聞標題創作”場景中排名墊底。
每日經濟新聞作為中國主流財經媒體,早在2020年就提出 “AI化+視頻化”的科技智媒轉型戰略,陸續推出每經AI快訊系統,每經AI電視,雨燕智宣——AI短視頻自動生成平臺,智能媒資庫等一系列AI產品,贏得市場贊譽。同時,在生成式AI爆發后,每經眾多采編人員深耕大模型領域,涌現了30余位優秀的提示工程師和技術工程師。專業的財經新聞采編能力與不斷深耕的AI技術能力,為大模型評測提供了堅實保障。
后續,“每日經濟新聞大模型評測小組”將圍繞更多的大模型應用場景,定期發布大模型評測報告。
??????????
《每日經濟新聞大模型評測報告》目的,是關注企業和個人用戶的實際需求,通過評測大模型在實際應用場景中的表現,進而幫助用戶在工作、學習、生活等場景中,找到最合適的大模型工具,提升效率。
對此,“每日經濟新聞大模型評測小組”選取了GPT 4.0,百度文心,月之暗面等15款市場主流的國內外大模型,圍繞“財經新聞標題創作”“微博新聞寫作”“文章差錯校對”“財務數據計算與分析”四個財經新聞的主要應用場景,進行第一期測評。評測均通過各款大模型API端口,在每經科技自主開發的“雨燕智宣AI創作+”大模型測試臺上進行。評測結果出來后,由15位每日經濟新聞資深記者和編輯進行嚴格的人工核準、評分和排名。
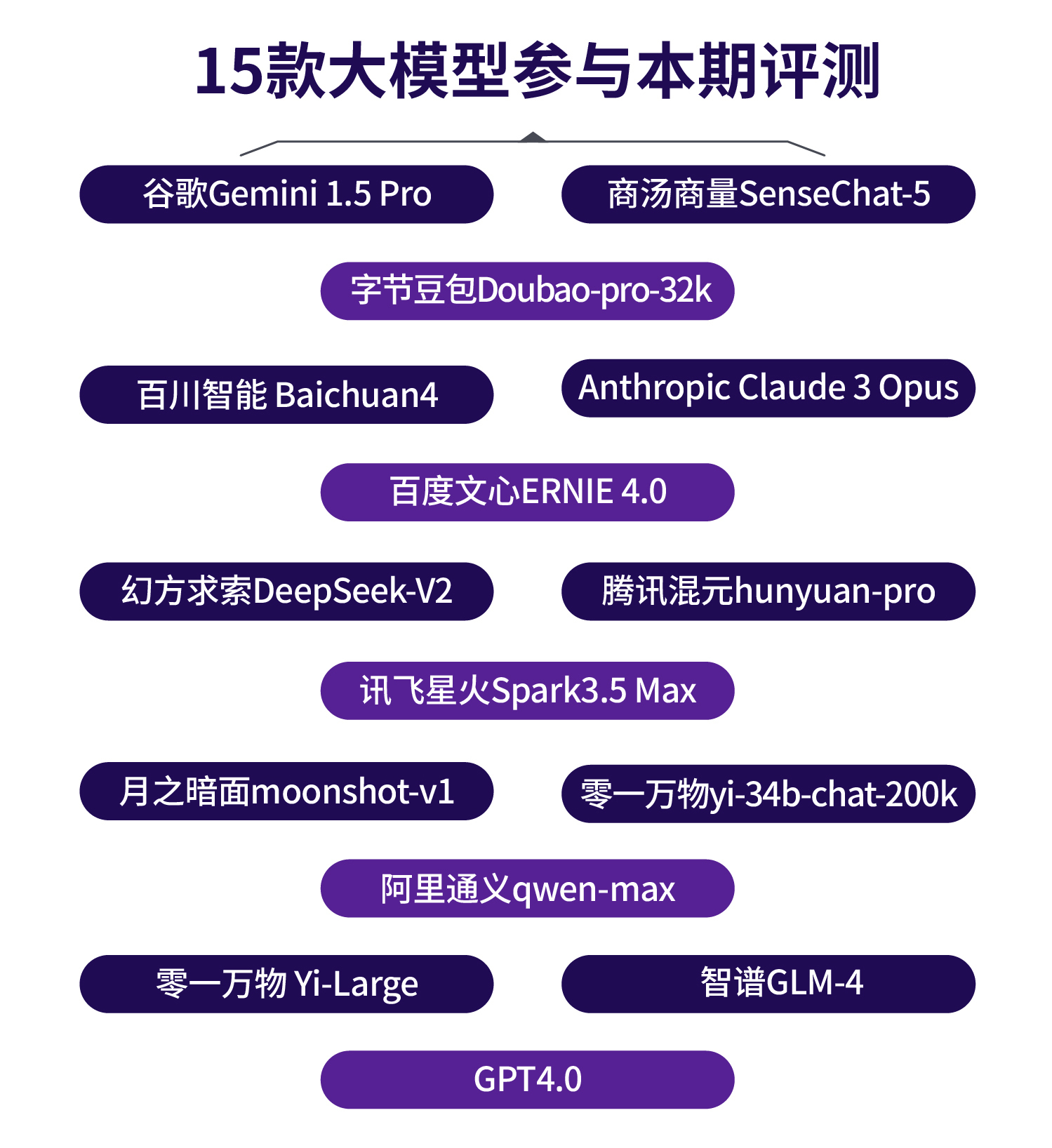
評測結果顯示,零一萬物 Yi-Large成為“黑馬”,總分排名第一。Anthropic Claude 3 Opus和幻方求索DeepSeek-V2分居第二、第三。各個大模型在不同場景和不同任務中的表現差異明顯。GPT 4.0的表現令人意外,僅名列倒數第五。
報告完整版以及測評題目,評分指標細則及部分案例,可訪問:每日經濟新聞大模型評測報告(第1期)
結論一:國產大模型正全面趕超
國產大模型正逐漸展現出其競爭力。與國外大模型相比,它們在多個任務上的表現已經顯示出趕超之勢。
國產大模型在多個測試場景中排名靠前。商湯商量SenseChat-5三次占據前五席位,兩次擊敗谷歌Gemini 1.5 Pro。在國外模型中,Anthropic Claude 3 Opus同樣在三個測評場景中排名前五,谷歌Gemini 1.5 Pro在“財經新聞標題創作”和“文章差錯校對”兩個場景中排名第一。令人意外的是,一直備受各界推崇的GPT 4.0卻在本次評測中整體表現不佳,在每個場景中都未能斬獲前五名,甚至在“財經新聞標題創作”中排名墊底。
“財經新聞標題創作”場景中,商湯商量SenseChat-5、字節豆包Doubao-pro-32k和百度ERNIE 4.0等,在信息提煉準確和重要新聞點突出方面與谷歌的Gemini 1.5 Pro不相上下。
“微博新聞寫作”場景中,百度文心ERNIE 4.0、商湯SenseChat-5等模型的總分與國外模型Anthropic Claude 3 Opus并列第一。
“文章差錯校對”場景中,零一萬物 Yi-Large是唯一一款得分超過100分的國產大模型。國產大模型比國外大模型更能理解漢語句式和表達規范。但在查找并修改錯別字、標點使用不當、數字和量詞錯誤、事實和信息錯誤等要求更精準的任務方面,還有提升空間。
“財務數據計算和分析”場景中,Anthropic Claude 3 Opus總分雖領先,但對幻方求索DeepSeek-V2和零一萬物Yi-Large的優勢并不大。尤其是幻方求索DeepSeek-V2成為此場景評測中一匹“黑馬”,其“財務數據分析”能力突出。
結論二:大模型各有專長
不同模型在特定場景、特定維度、特定指標上的表現差異顯著。體現了它們在各自領域的專長。
例如,谷歌Gemini 1.5 Pro在“財經新聞標題創作”和“文章差錯校對”兩大場景中排名第一。在“微博新聞寫作”場景中,該模型整體排名靠后。
Anthropic Claude 3 Opus、幻方求索DeepSeek-V2、百川智能Baichuan4則顯示出了強大的數據計算能力。
結論三:在跨語言環境下差異明顯
以“微博新聞寫作”場景為例,百度文心ERNIE 4.0、商湯商量SenseChat-5與Anthropic Claude 3 Opus并列第一。這反映了國產大模型在微博這一國內社交媒體場景下的卓越表現。國產大模型更能夠準確把握微博用戶的內容偏好和交流方式,生成符合平臺特性和用戶期待的微博文案。
相比之下,谷歌Gemini 1.5 Pro在微博寫作的運營維度上得分為0,可能源于其對微博平臺特性和用戶行為的不熟悉。
在中文語境之下,GPT 4.0在全部4個場景中的排名均不理想。這一現象突顯了大模型在跨語言和文化環境中的適應性問題,也表明了國產大模型在本土化應用上具有天然優勢。
結論四:信息提取能力參差不齊
從文章中準確提取關鍵信息,是對大模型能力的一項關鍵挑戰。本期評測中“文章差錯校對”場景正包含了對這一能力的測試。
谷歌Gemini 1.5 Pro憑借其在錯別字、標點使用不當、數字和量詞錯誤、事實和信息錯誤的查找和糾錯方面與其他大模型拉開了差距。
相比之下,零一萬物Yi-Large在病句查找和糾錯方面則位居首位,本可以挑戰谷歌Gemini 1.5 Pro,但在錯誤查找方面的表現拖了后腿。
大模型信息提取能力的差異可能與模型的訓練數據、算法設計以及對語言細微差別的捕捉能力有關。增強大模型的信息提取能力,可以提高其生成結果的準確度,更能讓大模型適用于對準確性要求極高的新聞工作。
每日經濟新聞大模型評測小組
2024年6月
??????????
接下來,“每日經濟新聞大模型評測小組”將繼續深入探索大模型的無限可能,從實際應用場景出發,對各個大模型進行全方位的評測,并定期推出專業報告,帶來最前沿的洞察和發現。
在此,我們誠摯地邀請您,加入評測項目。
如果您是研發企業,想要展示自家大模型的實力,與其他大模型進行比拼,請將參評大模型的詳細信息發送至我們的郵箱:damoxing@nbd.com.cn。
如果您是大模型的使用者,請告訴我們您希望在哪些場景中使用大模型,或者希望我們測試大模型的哪些能力。打開每日經濟新聞App,在“個人中心”——“意見反饋”欄中留下您的想法和需求。
期待您的參與,共同探索大模型的無限可能。

如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













