每日經(jīng)濟(jì)新聞 2024-09-06 15:04:00
每經(jīng)記者 王嘉琦 每經(jīng)實習(xí)編輯 宋欣悅

一、評測場景與參評模型概述
6月25日《每日經(jīng)濟(jì)新聞大模型評測報告》第1期發(fā)布。第1期評測聚焦財經(jīng)新聞采編能力,對15款大模型在“財經(jīng)新聞標(biāo)題創(chuàng)作”“微博新聞寫作”“文章差錯校對”“財務(wù)數(shù)據(jù)計算與分析”四大應(yīng)用場景下的能力進(jìn)行了評測。第1期評測至今,國內(nèi)外大模型持續(xù)更新,能力不斷提升,同時也有新的大模型涌現(xiàn)。
與第1期一樣,《每日經(jīng)濟(jì)新聞大模型評測報告》第2期評測依然以考察大模型在財經(jīng)新聞應(yīng)用場景中的能力為目標(biāo)。
第2期評測設(shè)置了三個應(yīng)用場景:(1)金融數(shù)學(xué)計算;(2)商務(wù)文本翻譯;(3)財經(jīng)新聞閱讀。
每經(jīng)大模型評測小組為每個場景制定了相應(yīng)的評價維度和評分指標(biāo)。每日經(jīng)濟(jì)新聞10名資深記者、編輯根據(jù)評價維度和評分指標(biāo),對各款大模型在三大場景中的表現(xiàn)進(jìn)行評分,匯總各場景得分,最終得到參評大模型總分。
第2期評測中的任務(wù)以客觀題為主,絕大多數(shù)題目都有標(biāo)準(zhǔn)答案。同時,評價維度和評分標(biāo)準(zhǔn)也更加突出客觀性,盡量避免主觀性評價。
需要特別指出的是,本期評測是通過各款大模型的API端口,并在默認(rèn)溫度下完成。與公眾用戶使用的大模型C端對話工具存在差異。但是評測結(jié)果對用戶在具體場景中選擇合適的大模型工具,依然具有重大參考價值。
本期評測均在“雨燕智宣AI創(chuàng)作+”測試臺上進(jìn)行,一共有15款大模型參與,包括:
GPT-4o、智譜GLM-4-0520、百度文心ERNIE-4.0-Turbo、阿里通義qwen-max、商湯商量SenseChat V5.5、訊飛星火Spark 4.0 Ultra、騰訊混元hunyuan-pro、月之暗面moonshot-v1、百川智能Baichuan4、零一萬物Yi-Large、Anthropic Claude 3.5 Sonnet、幻方求索DeepSeek-V2、字節(jié)豆包Doubao-pro-32k-240615、昆侖天工SkyChat-3.0、谷歌Gemini 1.5 Pro。
本期評測時間為2024年8月12日,因此上述參評大模型中的所有國內(nèi)大模型均為截至8月12日的最新版本。

二、評測結(jié)果
評測結(jié)果顯示,“黑馬”幻方求索DeepSeek-V2以237.75的總分位居榜首,緊隨其后的是騰訊混元hunyuan-pro(237.08分)和Anthropic Claude 3.5 Sonnet(234.42分)。
在專項能力方面,各模型展現(xiàn)出了不同的優(yōu)勢。
金融數(shù)學(xué)計算方面,騰訊混元hunyuan-pro以78分的成績領(lǐng)先其他模型。商務(wù)文本翻譯場景中,Anthropic Claude 3.5 Sonnet以91.67分的高分遠(yuǎn)超其他模型。昆侖天工SkyChat-3.0在財經(jīng)新聞閱讀場景中得分最高,達(dá)到87.75分。

1、評測場景一:金融數(shù)學(xué)計算
(1)評測任務(wù)及評分指標(biāo)
13.8%和13.11%哪個大?這道小學(xué)生難度的數(shù)學(xué)題,曾難倒了一眾海內(nèi)外大模型。不禁讓人思考,大模型在數(shù)學(xué)計算方面,到底是什么水平?
在實際應(yīng)用中,數(shù)學(xué)計算往往不是以“13.8%和13.11%哪個大”這樣的形式出現(xiàn),而是出現(xiàn)在具體行業(yè)和具體業(yè)務(wù)場景中。
對于每日經(jīng)濟(jì)新聞來說,財經(jīng)新聞報道常常涉及金融證券行業(yè)相關(guān)的數(shù)學(xué)計算。因此,評測小組選擇“金融數(shù)學(xué)計算”作為本期評測的第二個場景,一方面考察各款大模型的數(shù)學(xué)計算能力,另一方面也檢驗大模型對金融證券相關(guān)概念的理解。
評測小組設(shè)置了10道題目,其中絕大多數(shù)來自證券從業(yè)資格考試真題或模擬題,覆蓋股票市盈率、市凈率、基金資產(chǎn)凈值以及可轉(zhuǎn)換債券轉(zhuǎn)換價格計算等。這些題目需要大模型精確理解金融證券概念,還要求大模型能夠給出正確的計算公式和計算結(jié)果。
在評分標(biāo)準(zhǔn)方面,評測小組要求每款大模型分別進(jìn)行兩次獨(dú)立的回答。每題滿分為10分(公式正確得3分,結(jié)果正確得7分),總分共計100分。最終成績按兩次得分的平均分進(jìn)行排名。
(2)評測結(jié)果
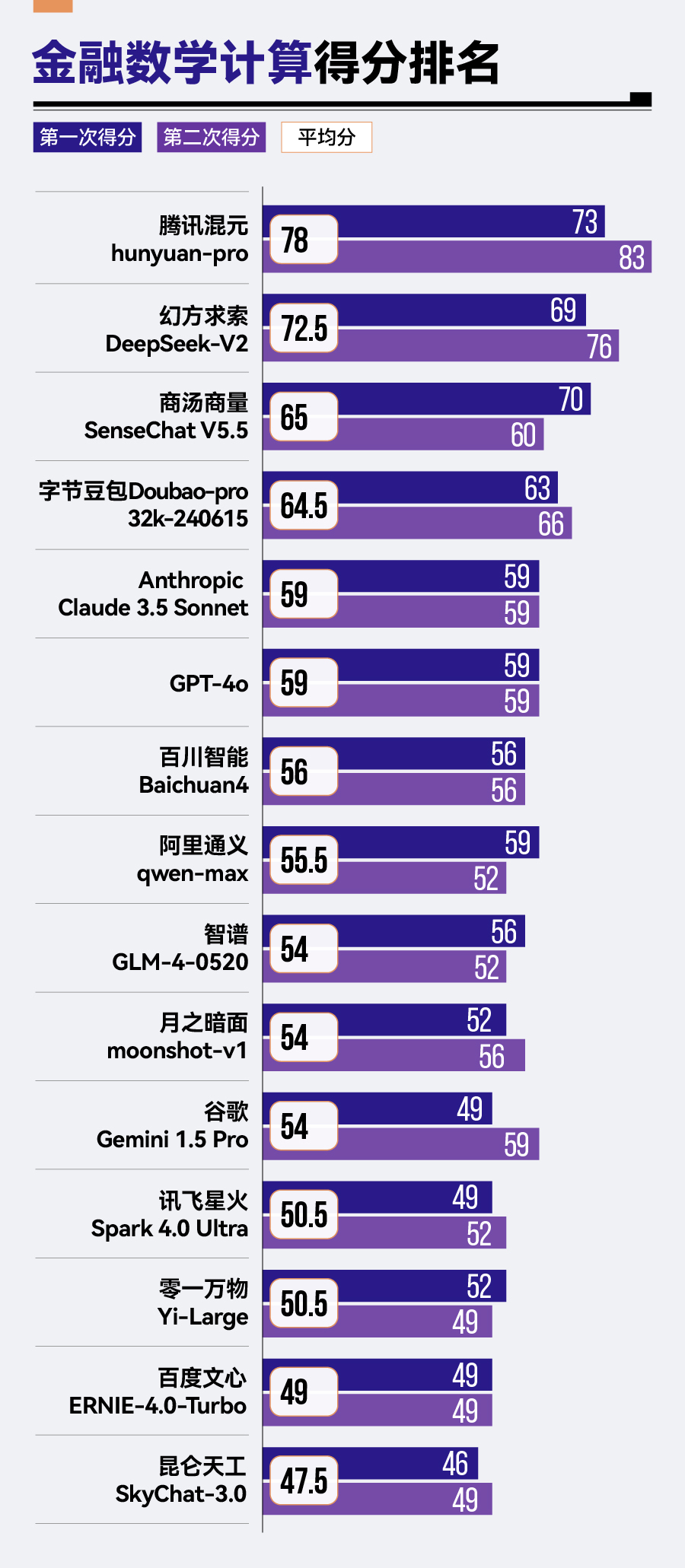
(3)結(jié)果分析
從整體排名來看,參評大模型在數(shù)學(xué)計算能力上仍有較大的提升空間。15款大模型中,僅有騰訊混元hunyuan-pro、幻方求索DeepSeek-V2、商湯商量SenseChat V5.5、字節(jié)豆包Doubao-pro-32k這4款大模型及格,超過了60分。其中,騰訊混元hunyuan-pro以78分排名第一,幻方求索DeepSeek-V2以72.5分緊隨其后。
相比之下,零一萬物的Yi-Large、百度的文心ERNIE-4.0-Turbo以及昆侖天工的SkyChat-3.0則在金融數(shù)學(xué)計算方面表現(xiàn)稍顯遜色,分別位列倒數(shù)第三、倒數(shù)第二與倒數(shù)第一的位置。
與第1期評測中的計算題“財務(wù)數(shù)據(jù)計算和分析”排名對比,騰訊混元hunyuan-pro與字節(jié)豆包Doubao-pro-32k在計算方面有較大提升。具體而言,騰訊混元hunyuan-pro尤為突出,從第1期的第六名一躍成為本期計算題的第一;字節(jié)豆包Doubao-pro-32k從第八名提升到第四名。
同時,經(jīng)過版本更新的商湯商量SenseChat系列,在第2期評測中也以SenseChat V5.5的新姿態(tài)亮相,并實現(xiàn)從原先第十四名到第三名的巨大跨越。
上一期的“黑馬”幻方求索DeepSeek-V2依然表現(xiàn)出突出且穩(wěn)定的計算能力,在兩期評測的計算題中均排名第二名。
與之形成鮮明對比的是,零一萬物Yi-Large在上期評測的計算題中排名第三,但在此次評測中遭遇“滑鐵盧”,降到了倒數(shù)第三名。
從具體題目分析,對于用一步計算即可得到答案的簡單計算題,15款大模型均表現(xiàn)良好。
例如,問題1、問題2和問題3中,15款大模型均得到了滿分。
【問題1】一只股票每股市價10元,每股凈資產(chǎn)2元,每股收益0.5元,這只股票市盈率為多少?
【答案】20(倍)。市盈率指標(biāo)表示股票價格和每股收益的比率,該指標(biāo)揭示了盈余和股價之間的關(guān)系,用公式表達(dá)為:市盈率=每股市價/每股收益(年化),則市盈率=10/0.5=20。
【問題2】A公司的每股市價為8元,每股凈資產(chǎn)為4元,則A公司的市凈率倍數(shù)為多少?
【答案】2(倍)。市凈率=股價/每股凈資產(chǎn)=8/4=2
【問題3】如果某可轉(zhuǎn)換債券面額為1000元,規(guī)定其轉(zhuǎn)換比例為40,則轉(zhuǎn)換價格為多少元?
【答案】25(元)。轉(zhuǎn)換價格=可轉(zhuǎn)換債券面值/轉(zhuǎn)換比例=1000/40=25。
然而,面對計算公式復(fù)雜、步驟較多的題目時,不少大模型表現(xiàn)并不理想,導(dǎo)致分?jǐn)?shù)差距被拉開。如問題8。
【問題8】若法定存款準(zhǔn)備率6%,客戶提現(xiàn)比率10%,超額準(zhǔn)備率9%,則可求出貨幣乘數(shù)為多少?
【答案】4.4。貨幣乘數(shù)計算公式m=(1+Rc)/(Rd+Re+Rc)。
本題中,貨幣乘數(shù)m=(1+10%)/(6%+9%+10%)=4.4。其中,Rc表示現(xiàn)金漏損率(提現(xiàn)率),Rd表示法定準(zhǔn)備金率,Re表示超額準(zhǔn)備金率。
幻方求索DeepSeek-V2答:
-計算結(jié)果:<5.56>
-計算公式:貨幣乘數(shù)=1/(法定存款準(zhǔn)備率+客戶提現(xiàn)比率+超額準(zhǔn)備率)
-計算過程:貨幣乘數(shù)=1/(0.06+0.10+0.09)=1/0.25=4
除騰訊混元hunyuan-pro在此題得到滿分10分、阿里通義qwen-max、字節(jié)豆包Doubao-pro-32k得到3分外,其余12款大模型未能拿分。
此外,問題9讓許多大模型陷入了誤區(qū)。問題9的考點(diǎn)在于,百分?jǐn)?shù)作差的結(jié)果,應(yīng)該用百分點(diǎn)而非百分?jǐn)?shù)來表示。
【問題9】某銀行將存款利率從2%提高到2.15%,請問加息后的存款利率與加息前的存款利率相比,增長了多少?
【答案】0.15個百分點(diǎn)或15個基點(diǎn)(bp)
騰訊混元hunyuan-pro答:
**第9題**:存款利率增長計算。
-加息前后利率分別為$r_1=0.02$和$r_2=0.0215$。
-增長率$g=frac{r_2-r_1}{r_1}$。
根據(jù)以上分析我們可以得到如下方程:
**第9題**:增長率$g=frac{0.0215-0.02}{0.02}$。
讓我們開始計算。
**第9題**的計算結(jié)果顯示加息后的存款利率增長了7%。
幻方求索DeepSeek-V2答:
計算結(jié)果:<0.15%>
-計算公式:利率增長=加息后的利率-加息前的利率
-計算過程:利率增長=2.15%-2%=0.15%
月之暗面moonshot-v1答:
**計算結(jié)果:0.15個百分點(diǎn)**
-**計算公式:**利率增長=(加息后的存款利率-加息前的存款利率)/加息前的存款利率*100%
-**計算過程:**利率增長=(2.15%-2%)/2%*100%=0.15%/2%*100%=7.5%,即0.15個百分點(diǎn)
幻方求索DeepSeek-V2離正確答案僅一步之遙,但最終還是掉進(jìn)了“坑”里。而月之暗面moonshot-v1在第二次回答中,雖然計算公式錯誤,但出乎意料地得出正確結(jié)果。
2、評測場景二:商務(wù)文本翻譯
(1)評測任務(wù)及評分指標(biāo)
英漢互譯也是一個大模型高頻使用場景。然而,翻譯質(zhì)量的評估常面臨主觀性強(qiáng)及標(biāo)準(zhǔn)不一的挑戰(zhàn)。為使評價標(biāo)準(zhǔn)盡量客觀,每經(jīng)評測小組選定“商務(wù)文本翻譯”作為測評場景,以翻譯的專業(yè)性和精確度為主要標(biāo)準(zhǔn)。
文本選擇方面,評測小組選取上市公司公告、協(xié)議和法律條款和科技類文章這類對準(zhǔn)確性要求高的文本。此外,這些文本均可在公司官網(wǎng)獲取英、漢兩個官方版本,可為評分提供客觀參考。
文本一:《小鵬汽車與大眾汽車集團(tuán)簽訂電子電氣架構(gòu)技術(shù)戰(zhàn)略合作框架協(xié)議》
英文文本鏈接:
中文文本鏈接:
https://www.xiaopeng.com/news/company_news/5289.html?reserve_source=168801
文本二:《解碼GAN如何掀起生成式AI革命浪潮》
英文文本鏈接:
https://blogs.nvidia.com/blog/ai-decoded-gan-canvas-app/
中文文本鏈接:
https://blogs.nvidia.cn/blog/ai-decoded-gan-canvas-app/
文本三:《Apple隱私政策(節(jié)選)》
英文文本鏈接:
https://www.apple.com/legal/privacy/en-ww/
中文文本鏈接:
https://www.apple.com/legal/privacy/szh/
在評分標(biāo)準(zhǔn)方面,評測小組專注準(zhǔn)確性和意義完整性,即信達(dá)雅中的“信”,而不關(guān)注主觀性評價過高的“達(dá)”和“雅”。
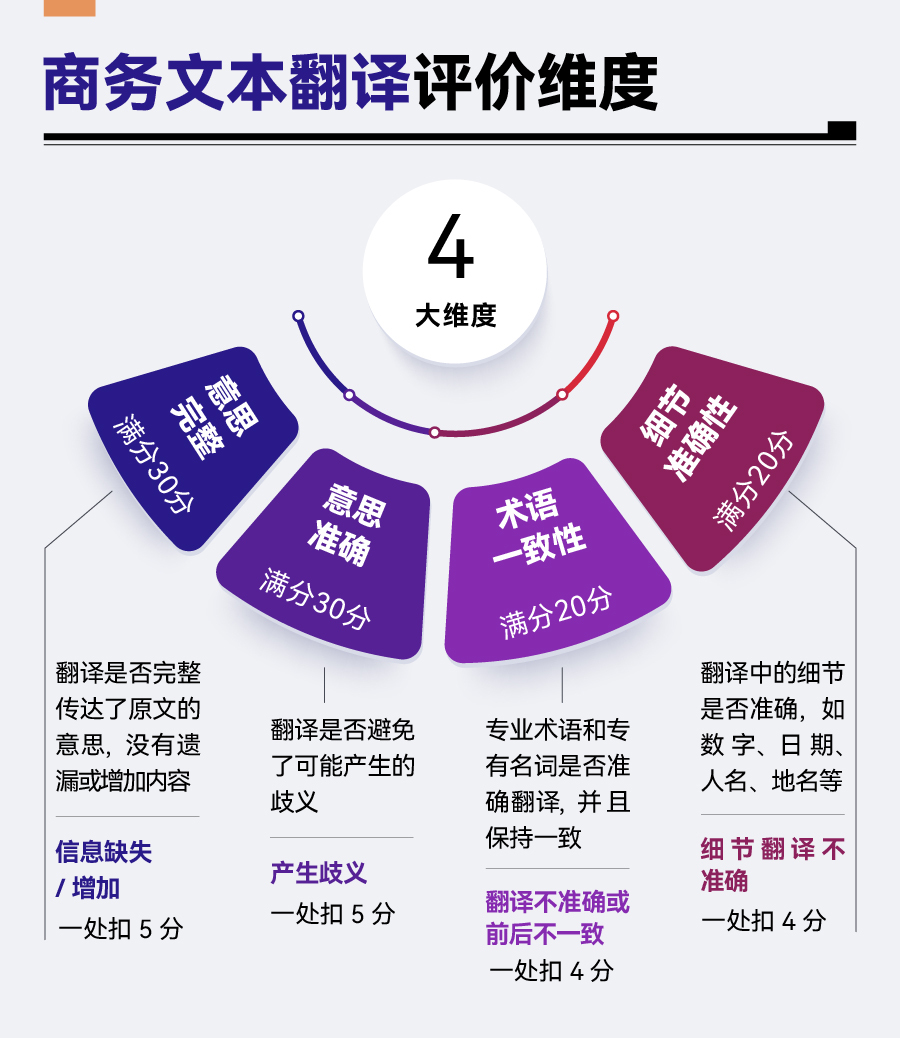
每款大模型分別對三篇文本的英、漢兩個版本進(jìn)行翻譯,完成共六次翻譯任務(wù)。隨后,依據(jù)“意思完整”“意思準(zhǔn)確”“術(shù)語一致性”“細(xì)節(jié)準(zhǔn)確性”四項維度,對每次翻譯結(jié)果進(jìn)行評估。每個維度均設(shè)有具體的評分細(xì)則(見下圖)。最終,按六次成績的平均分進(jìn)行排名,總分滿分100分。
(2)評測結(jié)果
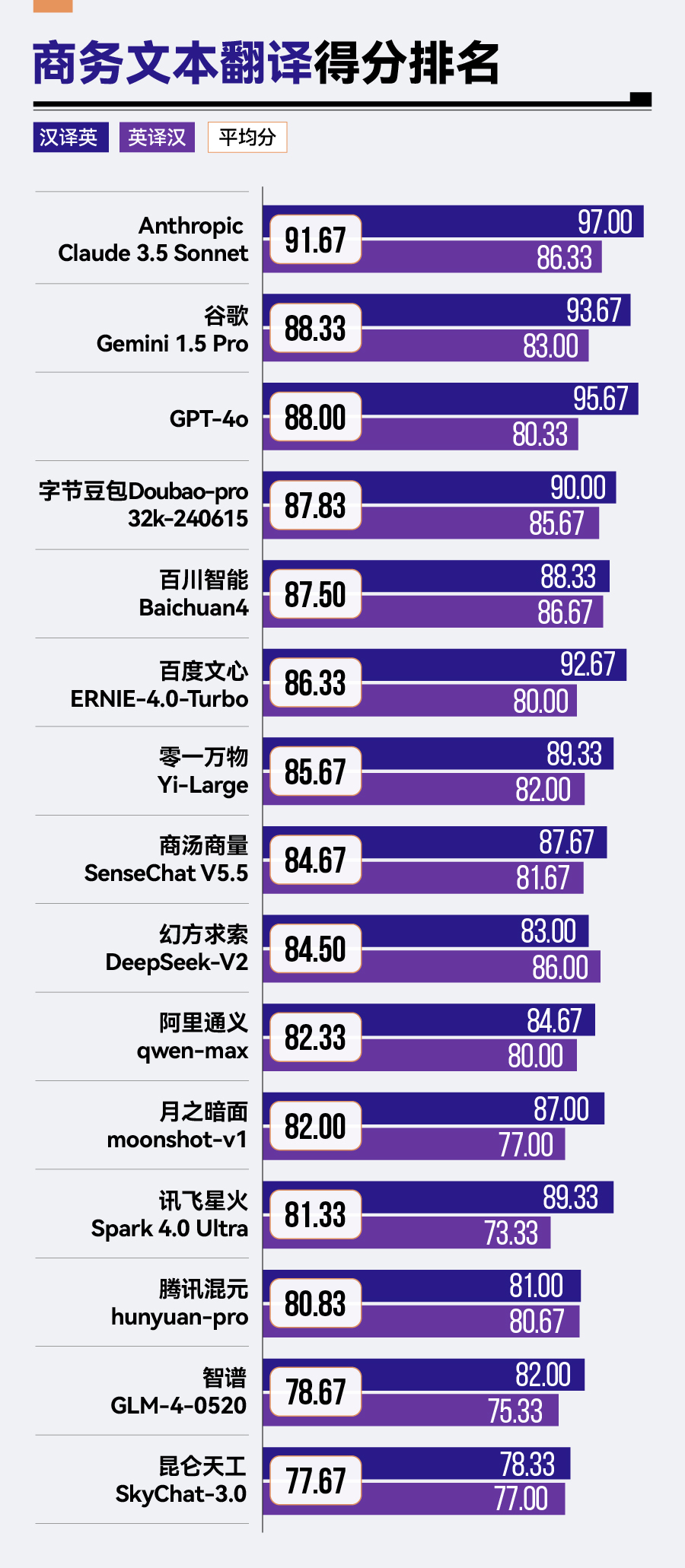
(3)結(jié)果分析
整體來看,參評大模型表現(xiàn)了較高的翻譯水平,平均分達(dá)到了84.5分。15款大模型中,有13款大模型平均分超過了80分。
其中,Anthropic Claude 3.5 Sonnet以91.67分的高分排名第一,谷歌Gemini 1.5 Pro、GPT-4o、字節(jié)豆包Doubao-pro-32k緊隨其后,均展現(xiàn)了不俗的翻譯實力。值得注意的是,前三名均為海外大模型。
然而,騰訊混元hunyuan-pro、智譜GLM-4與昆侖天工SkyChat-3.0在該場景下的表現(xiàn)則稍顯遜色,分別位于榜單的后三位。
絕大多數(shù)大模型在漢譯英任務(wù)上的表現(xiàn)要優(yōu)于英譯漢。除幻方求索DeepSeek-V2外,其余14款大模型均在漢譯英任務(wù)上,取得了更高的分?jǐn)?shù)。
在英譯漢任務(wù)中,評測小組觀察到,海外大模型展現(xiàn)出了對英語特殊表達(dá)方式,尤其是雙關(guān)語的深刻理解與精準(zhǔn)翻譯能力。
具體而言,文本二《解碼GAN如何掀起生成式AI革命浪潮》的英文標(biāo)題“Decoding How the Generative AI Revolution BeGAN”巧妙運(yùn)用了英語雙關(guān)語。
在這句話中,“BeGAN”是一個雙關(guān)語的使用方式,結(jié)合了“began”(開始)和“GAN”(Generative Adversarial Network,生成對抗網(wǎng)絡(luò))的詞匯特征。這句話的意圖是揭示生成式人工智能革命是如何開始的,而GAN是這一革命的重要組成部分。通過“BeGAN”的巧妙使用,標(biāo)題不僅傳達(dá)了生成式AI的起源,同時突出了GAN在這一過程中扮演的關(guān)鍵角色。
【原文】Decoding How the Generative AI Revolution BeGAN
【答案】解碼GAN如何掀起生成式AI革命浪潮
Anthropic Claude 3.5 Sonnet答:
解密生成式AI革命如何始于GAN
GPT-4o答:
解碼生成式AI革命的起點(diǎn):GAN
百度文心ERNIE-4.0-Turbo答:
生成式AI革命如何拉開序幕
字節(jié)豆包Doubao-pro-32k答:
解讀生成式人工智能革命如何開啟
Anthropic Claude 3.5 Sonnet和GPT-4o兩款海外大模型都能較好地理解雙關(guān)語,并對其進(jìn)行準(zhǔn)確翻譯。而國內(nèi)大模型中,整體表現(xiàn)優(yōu)異的百度文心ERNIE-4.0-Turbo和字節(jié)豆包Doubao-pro-32k也并沒有很好地翻譯出這一雙關(guān)語。
不過,各款大模型在英譯漢中的得分差距不大,真正使總分拉開差距的是漢譯英,且國外大模型的表現(xiàn)要普遍優(yōu)于國內(nèi)大模型。
在漢譯英中,三款海外大模型得分都超過90分。其中,總排名第一的Anthropic Claude 3.5 Sonnet漢譯英得分97分。相比之下,昆侖天工SkyChat-3.0在該任務(wù)上僅得到了78.33分,相差近20分。
從具體文本分析,在漢譯英任務(wù)中,最能拉開分?jǐn)?shù)差距的是文本三《Apple隱私政策(節(jié)選)》。文本三屬于法律文本,其通常具有高邏輯性和結(jié)構(gòu)性,在詞匯的使用上也非常嚴(yán)謹(jǐn),通常避免使用模糊或容易引起歧義的表達(dá)。
三款海外大模型——Anthropic Claude 3.5 Sonnet、谷歌Gemini 1.5 Pro以及GPT-4o均在該任務(wù)上均得到100分。
深入分析具體的評價維度,評測小組發(fā)現(xiàn),“意思準(zhǔn)確”與“術(shù)語一致性”成為了拉開分?jǐn)?shù)差距的兩大核心要素。
在“意思準(zhǔn)確”維度上,零一萬物Yi-Large、昆侖天工SkyChat-3.0、智譜GLM-4在文本三《Apple隱私政策(節(jié)選)》漢譯英任務(wù)中表現(xiàn)欠佳。
比如:
【原文】此外,Apple不會為了第三方的營銷目的與第三方共享個人數(shù)據(jù)。
零一萬物Yi-Large答:
Additionally,Apple does not share personal data with third parties for marketing purposes.
原文中的“第三方的營銷目的”是強(qiáng)調(diào)Apple不會為了第三方的營銷目的而共享數(shù)據(jù),而不是“Apple的營銷目的”。零一萬物Yi-Large的翻譯“for marketing purposes”未明確指出這是第三方的營銷目的,使得信息有些模糊。
在“術(shù)語一致性”維度上,就連排名國內(nèi)大模型總平均分第二的百川智能Baichuan4和在國內(nèi)大模型漢譯英單項排名第一的百度文心ERNIE-4.0-Turbo,也未能展現(xiàn)出令人完全滿意的水平。
比如:
【原文】Apple附屬公司
【答案】Apple affiliates或Apple-affiliated companies
百川智能Baichuan4、百度文心ERNIE-4.0-Turbo、零一萬物Yi-Large、騰訊混元hunyuan-pro、月之暗面moonshot-v1、智譜GLM-4答:
Apple subsidiaries
這里的“Apple附屬公司”指與Apple有正式業(yè)務(wù)關(guān)系的公司。這可能包括子公司、姊妹公司或其他通過所有權(quán)或合作伙伴關(guān)系與蘋果公司有關(guān)聯(lián)的實體,術(shù)語范圍較廣。
“affiliates”通常用于描述廣泛的企業(yè)關(guān)系,包括子公司、關(guān)聯(lián)公司、聯(lián)營公司等。但“subsidiaries”特指由母公司完全或部分控股的子公司。
在“意思完整”維度上,幻方求索DeepSeek-V2、昆侖天工SkyChat-3.0相對來說,表現(xiàn)欠佳。
比如:
【原文】在有合法依據(jù)的情況下,如果我們確定披露對于執(zhí)行我們的條款和條件或保護(hù)我們的運(yùn)營或用戶是合理必要的,或者在重組、合并或出售活動中是合理必要的,我們也可能會披露關(guān)于你的信息。
幻方求索DeepSeek-V2答:
We may also disclose information about you if we determine that disclosure is reasonably necessary to enforce our terms and conditions or protect our operations or users,or if it is reasonably necessary in the context of a reorganization,merger,or sale.
原文提到了“在有合法依據(jù)的情況下”,這是法律條款中的重要限定詞,表明信息披露必須基于法律基礎(chǔ)。
幻方求索DeepSeek-V2的翻譯中缺少這一內(nèi)容。
在“細(xì)節(jié)準(zhǔn)確性”維度上,騰訊混元hunyuan-pro、月之暗面moonshot-v1以及字節(jié)豆包Doubao-pro-32k的表現(xiàn)有待提升。
比如:
【原文】其他。
【答案】Others.
騰訊混元hunyuan-pro答:
Other.
在這里,“others”作為代詞在法律條款中使用時更加明確和完整,尤其在涉及到第三方或其他未明確提到的實體或個人時,它表明了文件所指的范圍。
而騰訊混元hunyuan-pro譯為了“other”,在細(xì)節(jié)的處理上并不到位。因為在法律條款中,單獨(dú)使用“other”可能會引發(fā)歧義,因為它沒有明確指出與什么相對的“其他”,通常需要一個后續(xù)的名詞來使其含義完整,如“other conditions”。
而對于句子長度普遍不長、邏輯相對簡單清晰的文本,絕大多數(shù)大模型表現(xiàn)良好。
例如,在文本二《解碼GAN如何掀起生成式AI革命浪潮》的漢譯英任務(wù)中,13款大模型得分達(dá)90分及以上,其中還有款大模型獲得滿分。
3、評測場景三:財經(jīng)新聞閱讀
(1)評測任務(wù)及評分指標(biāo)
在日常使用中,用戶利用大模型快速閱讀文章并提供相關(guān)信息是一個多頻場景。這要求大模型能夠快速、準(zhǔn)確且穩(wěn)定地提取文章信息。
本期評測的第一個場景“財經(jīng)新聞閱讀”旨在檢驗各款大模型精準(zhǔn)捕捉信息的能力。為此,評測小組選取了兩篇每日經(jīng)濟(jì)新聞的財經(jīng)新聞稿,并針對每篇文章設(shè)置了5道問答題,要求大模型閱讀新聞稿后進(jìn)行答題。
文章一:《資本市場迎來第三個“國九條”,會有第三次“大牛市”嗎?》
文章二:《負(fù)利率落幕!日本央行8年超寬松試驗復(fù)盤,17年來首次加息將產(chǎn)生哪些影響》
每篇文章篇幅約4000字。所有題目均能從文章中找到答案,一部分問題的答案明確位于文章中某個位置;而另一部分問題的答案則分散在文章多個段落,考察大模型對關(guān)鍵信息的提煉整合能力。
在評分標(biāo)準(zhǔn)方面,評測小組要求每款大模型分別對兩篇文章各進(jìn)行兩次獨(dú)立的閱讀和答題,每篇文章對應(yīng)5道問答題,每題滿分10分,總分50分。隨后,評測小組依據(jù)得分點(diǎn),對兩次回答結(jié)果分別進(jìn)行評分。最終,按兩次答題的平均分之和進(jìn)行排名,總分滿分100分。由于所有題目的答案均能從文章中找到明確的答案,因此評分不存在主觀判斷。
(2)評測結(jié)果
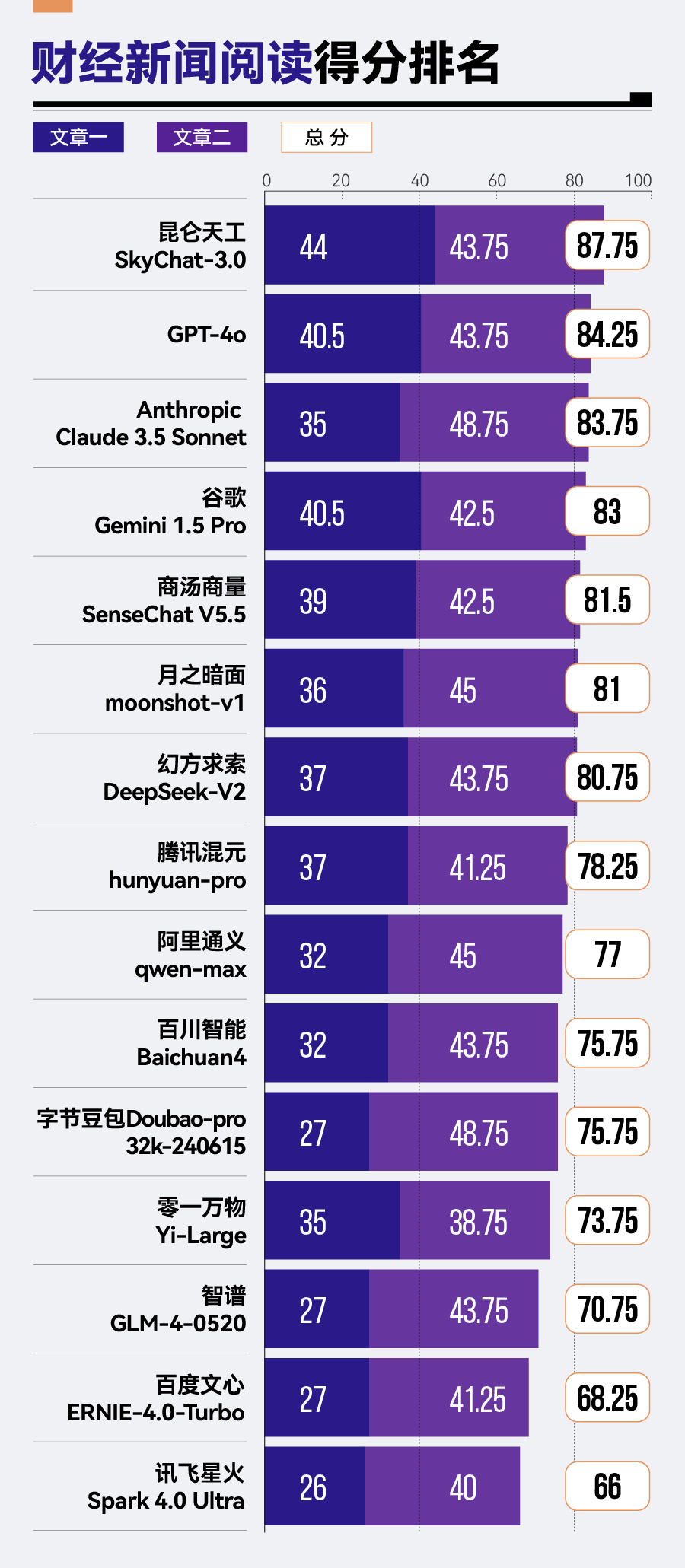
(3)結(jié)果分析
在該場景下,本期評測新加入的大模型——由昆侖萬維研發(fā)的昆侖天工SkyChat-3.0——以總分87.75分排名第一。GPT-4o、Anthropic Claude 3.5 Sonnet、谷歌Gemini 1.5 Pro三款海外大模型緊隨其后。相比之下,智譜GLM-4、百度文心ERNIE-4.0-Turbo及訊飛星火Spark 4.0 Ultra在此方面的表現(xiàn)則稍顯不足,分列該場景排名的后三位。
評分結(jié)果體現(xiàn)了一個突出特點(diǎn):各款大模型在文章二任務(wù)中的得分差距不大。真正拉開差距的是文章一任務(wù)。這說明,對于大多數(shù)模型來說,文章一的內(nèi)容及其題目難度更大。總分排名靠前的大模型在兩篇文章任務(wù)中表現(xiàn)更加穩(wěn)定,說明這些大模型可以更好地應(yīng)對不同難度的任務(wù)。
從具體題目分析,對得分點(diǎn)單一的題目,絕大多數(shù)大模型表現(xiàn)良好且穩(wěn)定。
例如,針對文章二的題目一,14款大模型得到了滿分。
【問題1】日本央行負(fù)利率政策持續(xù)了多少年?日本退出負(fù)利率政策后,全球還有哪些央行在執(zhí)行負(fù)利率?
【答案】這標(biāo)志著日本央行正式退出維持8年之久的負(fù)利率政策(5分)。這也意味著,全球再無負(fù)利率(5分)。
再如,文章二的題目二,15款大模型全部得到滿分。
【問題2】日本央行的負(fù)利率是什么意思?負(fù)利率政策下,儲戶在銀行存錢還要倒貼錢給銀行嗎?
【答案】日本央行所謂的負(fù)利率,針對的是金融機(jī)構(gòu)準(zhǔn)備金賬戶中部分資金實行-0.1%的利率。(5分)也就是說,這個利率是日本央行跟商業(yè)銀行之間的利率,跟個人儲戶沒有直接關(guān)系,并不是儲戶在銀行存錢還要“倒貼銀行錢”。(5分)
各款大模型在文章一任務(wù)中的得分差距大,主要因為題目四。題目四的得分點(diǎn)分散,需要大模型從文章多處提取到相關(guān)信息并進(jìn)行歸納總結(jié)。對此,大多數(shù)模型的表現(xiàn)不理想,如字節(jié)豆包Doubao-pro-32k和Anthropic Claude 3.5 Sonnet。相比之下,昆侖天工SkyChat-3.0在第二次生成時,給出了較為完整的答案。
【問題4】資本市場業(yè)內(nèi)認(rèn)為,前兩次“國九條”的重點(diǎn)分別是什么?
【答案】第一次“國九條”:重點(diǎn)是推進(jìn)資本市場改革開放。(1分)核心是擴(kuò)大直接融資、積極穩(wěn)妥解決股權(quán)分置問題。(2分)重在推動資本市場發(fā)展。(1分)
第二次“國九條”:著眼于促進(jìn)資本市場健康發(fā)展。(1分)核心是擴(kuò)大市場雙向開放、鼓勵并購重組、混合所有制、放松私募發(fā)行審批。(4分)重在保護(hù)中小投資者利益。(1分)
字節(jié)豆包Doubao-pro-32k答:
第一次“國九條”重點(diǎn)是推進(jìn)資本市場改革開放(1分);第二次“國九條”著眼于促進(jìn)資本市場健康發(fā)展(1分)。
Anthropic Claude 3.5 Sonnet答:
-2004年"國九條":推進(jìn)資本市場改革開放(1分)。
-2014年"國九條":促進(jìn)資本市場健康發(fā)展(1分)。
昆侖天工SkyChat-3.0答:
-**2004年“國九條”**:重點(diǎn)在于擴(kuò)大直接融資,積極穩(wěn)妥解決股權(quán)分置問題(2分),推動資本市場改革開放(1分)。
-**2014年“國九條”**:核心在于擴(kuò)大市場雙向開放,鼓勵并購重組、混合所有制、放松私募發(fā)行審批(4分),促進(jìn)資本市場健康發(fā)展(1分)。
三、本期評測總結(jié)
1、大模型之間差距明顯
本次評測結(jié)果顯示,幻方求索DeepSeek-V2(237.75分)、騰訊混元hunyuan-pro(237.08分)、Anthropic Claude 3.5 Sonnet(234.42分)、GPT-4o(231.25分)和商湯商量SenseChat V5.5(231.17分)構(gòu)成第一梯隊。值得注意的是,排名靠前的模型中,國產(chǎn)大模型表現(xiàn)突出,與頂級海外模型實力相當(dāng)。
然而,從第一名到第十五名,總分差距達(dá)到了近40分,反映出大模型間仍存在顯著差距。而在單個場景中,在財經(jīng)新聞閱讀任務(wù)中,第一名昆侖天工SkyChat-3.0(87.75分)與最后一名訊飛星火Spark 4.0 Ultra(66分)相差21.75分。
2、數(shù)學(xué)計算能力成普遍短板
各款大模型數(shù)學(xué)計算方面普遍存在不足。15款參評模型中,僅有4款模型得分超過60分,其中騰訊混元hunyuan-pro以78分位居榜首。即使是在其他場景表現(xiàn)出色的模型,如Anthropic Claude 3.5 Sonnet和GPT-4o,在此項測試中也僅得到59分。
3、國內(nèi)大模型需提高外語能力
在商務(wù)文本翻譯任務(wù)中,海外模型展現(xiàn)出明顯優(yōu)勢。Anthropic Claude 3.5 Sonnet、谷歌Gemini 1.5 Pro和GPT-4o在漢譯英任務(wù)中得分均超過90分。相比之下,國內(nèi)模型表現(xiàn)相對遜色,尤其是在處理法律文本和雙關(guān)語等需要深層語言理解的內(nèi)容時。例如,在翻譯“Decoding How the Generative AI Revolution BeGAN”這樣存在雙關(guān)表達(dá)的標(biāo)題時,海外模型表現(xiàn)明顯優(yōu)于國內(nèi)模型。
4、通用大模型各項能力卻不均衡
第2期評測與第1期評測的場景、維度和標(biāo)準(zhǔn)不同,導(dǎo)致部分模型排名變化顯著。盡管都是通用大模型,但存在各項能力不均衡,“偏科”現(xiàn)象嚴(yán)重的情況。
比如,零一萬物Yi-Large兩期評測的表現(xiàn)波動較大。在第1期評測中,它以總分374.8分高居榜首,尤其在財務(wù)數(shù)據(jù)計算與分析任務(wù)中得到了126.4分的高分。然而在第2期評測中,其表現(xiàn)大幅下滑,特別是在金融數(shù)學(xué)計算任務(wù)中僅獲得50.5分,總排名也跌出了前五。
再如,昆侖天工SkyChat-3.0在財經(jīng)新聞閱讀中排名第一,但在金融數(shù)學(xué)計算中卻墊底(47.5分)。
騰訊混元hunyuan-pro的表現(xiàn)則展現(xiàn)了明顯的進(jìn)步。在第1期評測中,它的總分為298.5分,排名相對靠后。但在第2期評測中,騰訊混元hunyuan-pro以237.08分的總分位列第二,尤其在金融數(shù)學(xué)計算任務(wù)中以78分的成績領(lǐng)先其他模型。
相比之下,幻方求索DeepSeek-V2在兩次評測中都表現(xiàn)出色。在第1期評測中,它以總分335.2分排名第三;到第2期評測,更是以237.75分的成績躍居榜首。特別是在客觀性較強(qiáng)的任務(wù)上,如第1期的財務(wù)數(shù)據(jù)計算與分析(133.4分)和第2期的金融數(shù)學(xué)計算(72.5分),幻方求索DeepSeek-V2都保持了較高水平。
海外大模型中,Anthropic公司的Claude在兩次評測中都表現(xiàn)不俗,但排名有所變動。在第1期中,Anthropic Claude 3 Opus以361.2分排名第二;在第2期中,Anthropic Claude 3.5 Sonnet盡管在商務(wù)文本翻譯任務(wù)中表現(xiàn)出色(91.67分),但總體排名略有下降,以234.42分排在第三位。
每日經(jīng)濟(jì)新聞大模型評測小組
2024年9月
如需轉(zhuǎn)載請與《每日經(jīng)濟(jì)新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟(jì)新聞》報社授權(quán),嚴(yán)禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關(guān)注每日經(jīng)濟(jì)新聞APP

Copyright ? 2024 每日經(jīng)濟(jì)新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112












