每日經濟新聞 2024-09-14 00:31:48
每經記者 鄭雨航 每經編輯 程鵬 蘭素英
傳說中的“草莓”模型今天在沒有任何預告下忽然上線了!
OpenAI最新發布的模型名為o1,是系列推理模型的首批版本,現階段推出的是o1-preview(預覽版)和o1-mini(迷你版)。
目前,o1-preview和o1-mini已經面向ChatGPT Plus和Team訂閱用戶開放,而Enterprise和Edu用戶將于下周初獲得訪問權限。OpenAI表示,它計劃向ChatGPT的所有免費用戶提供o1-mini訪問權限,但尚未確定發布日期。
據OpenAI介紹,在解決問題的能力方面,o1模型比以往任何模型都更接近人類思維,并且能夠“推理”數學、編碼和科學任務。
為了驗證新模型的能力是否正如OpenAI所宣稱的那么強大,《每日經濟新聞》記者從經典“草莓測試”、代碼編寫、小游戲制作、數學與經濟學,以及事實性知識這五大維度對o1-preview模型進行了測試。
結果顯示,o1-preview表現出了超越OpenAI之前發布的大模型的編程和數學推理能力。例如,o1-preview能夠編寫出流暢運行的代碼,并且在復雜環境中依然能夠自行推理出解決方案。而且,記者在測試過程中也感覺到,o1-preview在人性化方面也有很大的提升,表現出了真人般的思考。不過,新模型也并非毫無缺點,在事實性知識測試就“翻車”了。?

當地時間9月12日,OpenAI發布了一款名為o1的新模型,這是其計劃中一系列“推理”模型中的第一個版本,也是此前業界盛傳已久的“草莓”模型。
?
圖片來源:X平臺
對于OpenAI來說,o1代表著它朝著類人AI的目標又邁出了一步。OpenAI認為,o1代表著一種全新的能力,這一能力被認為如此重要,以至于公司決定從當前的GPT-4模型重新開始,完全放棄了“GPT”品牌,從1開始命名。?
OpenAI表示,將從當前的GPT-4模型重新開始,“將計數器重置為 1”,甚至放棄了迄今為止定義了聊天機器人乃至整個生成式AI熱潮的“GPT”品牌。o1建立了一個能夠通過一系列離散步驟,謹慎而合乎邏輯地解決問題的系統,每個步驟都建立在上一個步驟的基礎上,類似于人類的推理方式。
OpenAI首席科學家Jakub Pachocki表示,之前的模型在收到用戶問詢時會立即開始回答。“而這個模型(指的是o1)會慢慢來。它思考問題,并嘗試分解問題,尋找角度,努力提供最佳答案。”這就像大多數人在幼年時被父母所要求的那樣,先想好再說話。
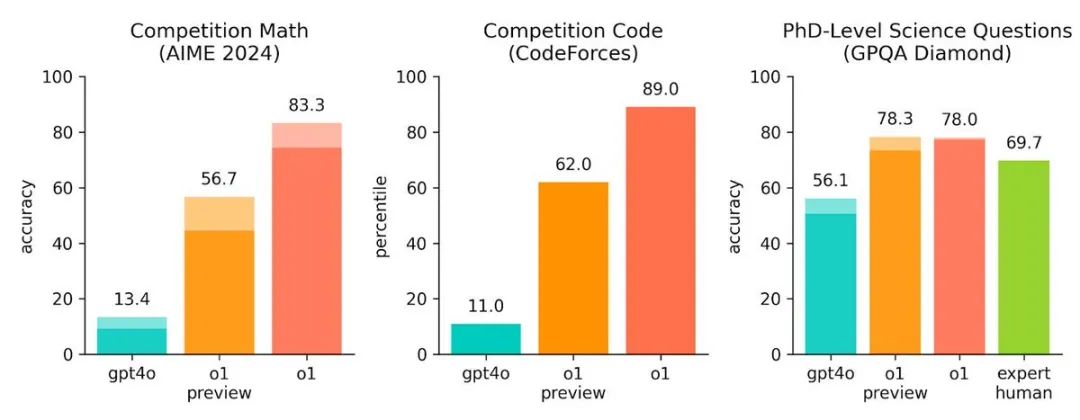
OpenAI表示,o1在競賽編程問題(Codeforces)中排名第89個百分點,在美國數學奧林匹克競賽(AIME)預選賽中位列美國前500名學生之列,并且在物理、生物和化學問題的基準測試(GPQA)中超過了人類博士水平的準確度。
在OpenAI發布的研究和博客文章中,o1看起來“推理”能力十分強大,不僅可解決高級數學和編碼問題,還能解密復雜的密碼,以及解答來自專家學者們關于遺傳學、經濟學和量子物理學的復雜問題。大量圖表顯示,在內部評估中,o1在編碼、數學和各個科學領域的問題上已經超越了公司最先進的語言模型GPT-4o,甚至可能超越了人類。
圖片來源:OpenAI官網
為了深入了解o1模型的強大能力,《每日經濟新聞》記者從經典草莓測試、代碼編寫、小游戲制作、數學與經濟學,以及事實性知識這五大維度對o1-preview模型進行了測試。?
1)草莓測試
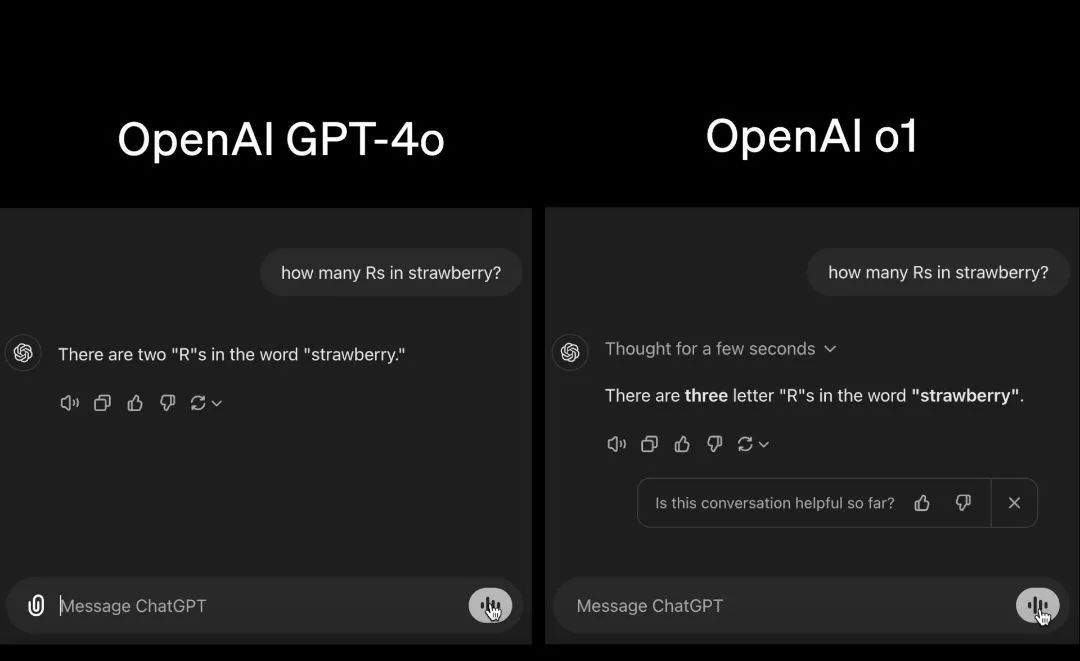
首先,記者用之前幾乎所有大模型都“翻車”的一道簡單題目進行了測試,即“單詞strawberry里面到底有幾個r”。從生成的結果看,o1-preview還是帶來了一點小驚喜的。
2)代碼編寫
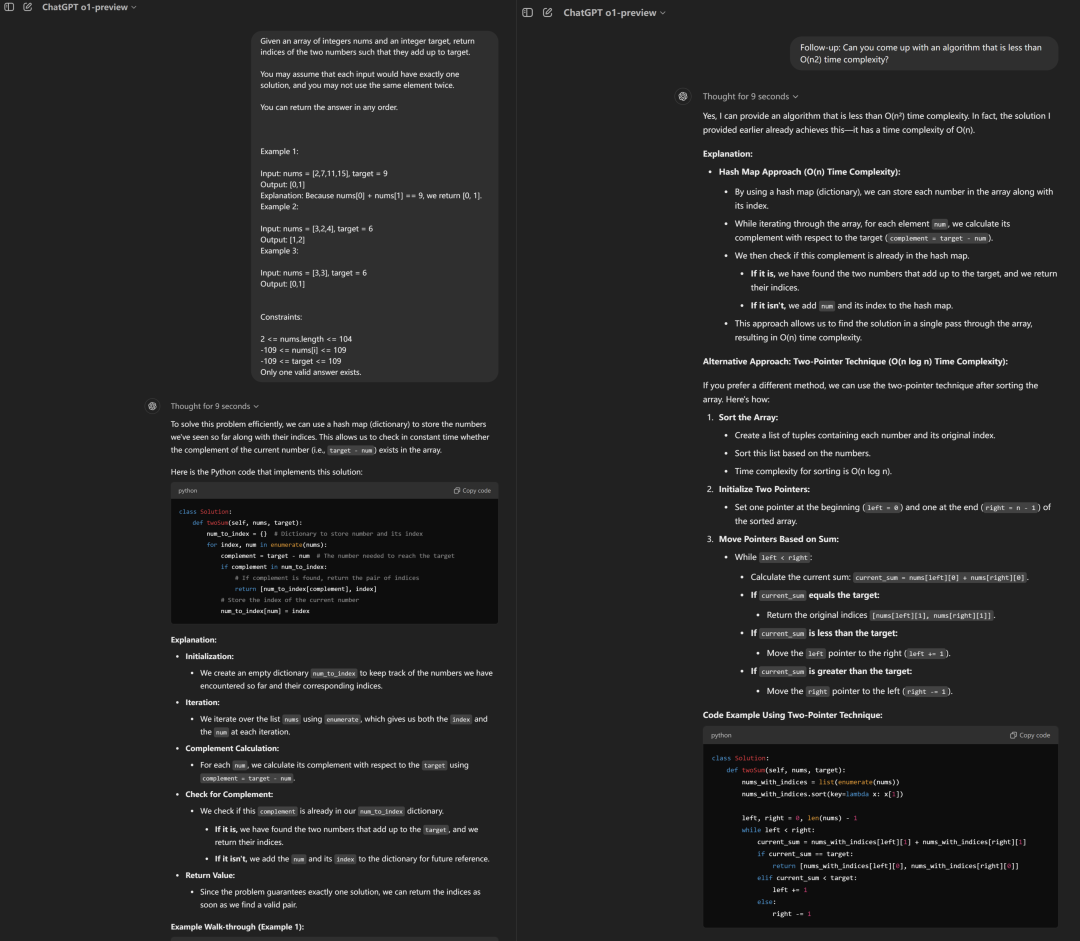
記者首先向o1-preview詢問了一個在線編程平臺leetcode里最有名的簡單算法題:Two Sum(兩數之和)問題。o1給出了很詳盡的推理過程和答案。
隨后記者故意要求優化答案,o1在思考9秒后意識到自己提供的已經是最優解法了,并就此進行了說明,另外還很“貼心”地提供了一個次優解。而在之前記者對其他模型的測試中,這些模型只會道歉然后將答案更改為次優解。
3)小游戲制作
在o1模型的演示中,OpenAI演示過“用一句話編寫小游戲”的功能。測試過程中,記者讓o1-preview幫忙介紹好用的代碼工具,并協助編寫一個乒乓小游戲。
o1-preview僅用了19秒就給出了一份能夠流暢運行的代碼,并且附上了學習指南和鼓勵的話語,非常地人性化。
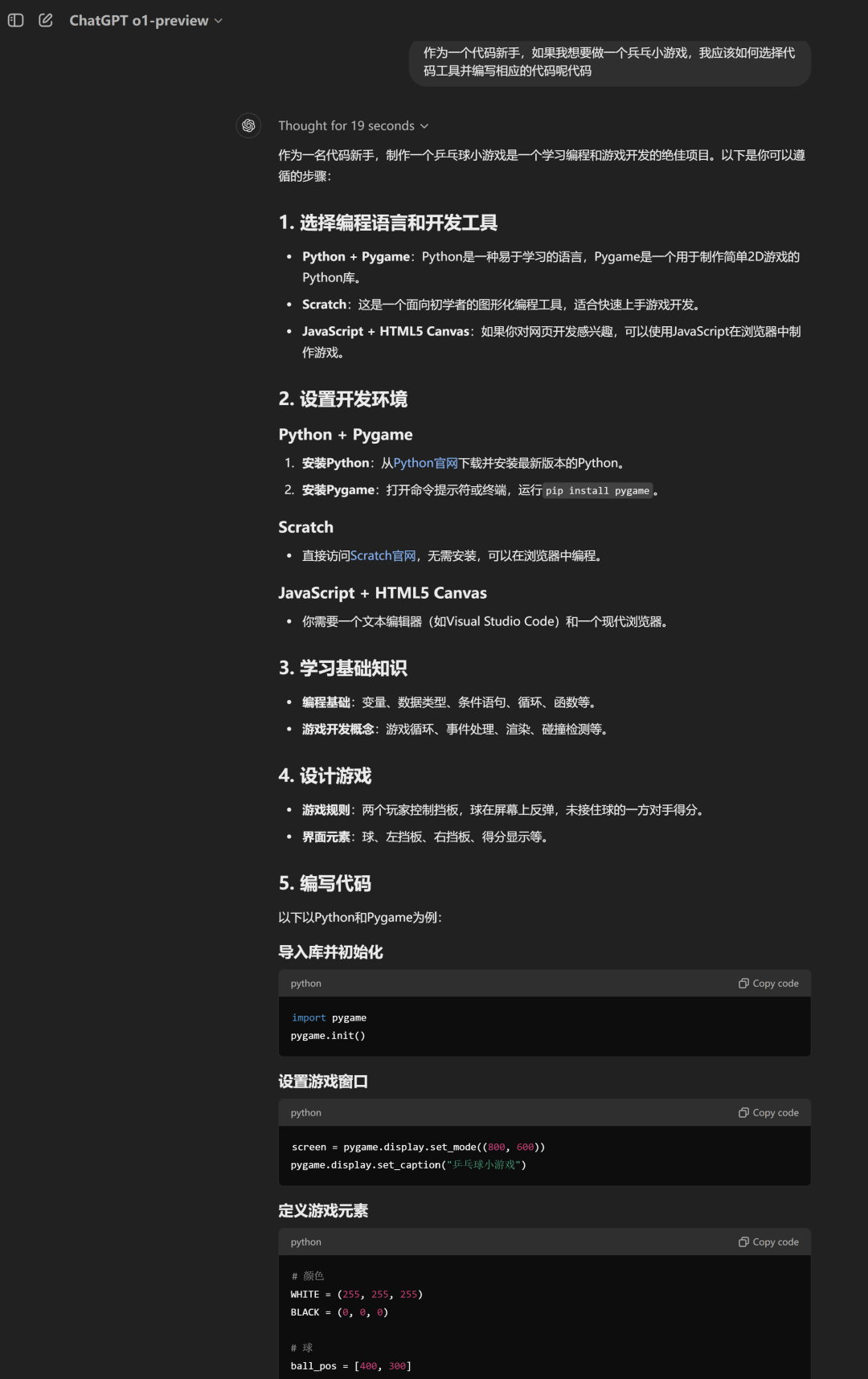
為避免o1-preview作弊,使用的是記憶能力,而不是使用推理能力進行回答,記者還請求o1-preview更換了一個代碼運行環境:jupyter note。這一運行環境是針對數據分析進行特化的python環境,開發人員基本不會使用此環境開發小游戲。
經過思考后,o1依然給出了一個可以運行的代碼。不過,相較于之前的代碼,這份答案有著不少的bug,但這也從側面說明這確實是思考出來的答案,而不是訓練過程中加入的標準答案。

為進一步驗證o1-preview的創新推理能力,記者隨后又要求模型在這個小游戲的基礎上開發一個更復雜有趣的小游戲。
這下,o1的表現真的有點驚喜。根據乒乓游戲的碰撞機制,該模型自行迭代出了一個向上登高的跳躍游戲。一般其他大模型需要用戶把需求描述清楚才會輸出一個比較好的答案,但記者在這次測試中沒有進行任何的額外提示,o1就輸出了一個能流暢運行,并且在記者眼中看來也足夠有趣的小游戲。
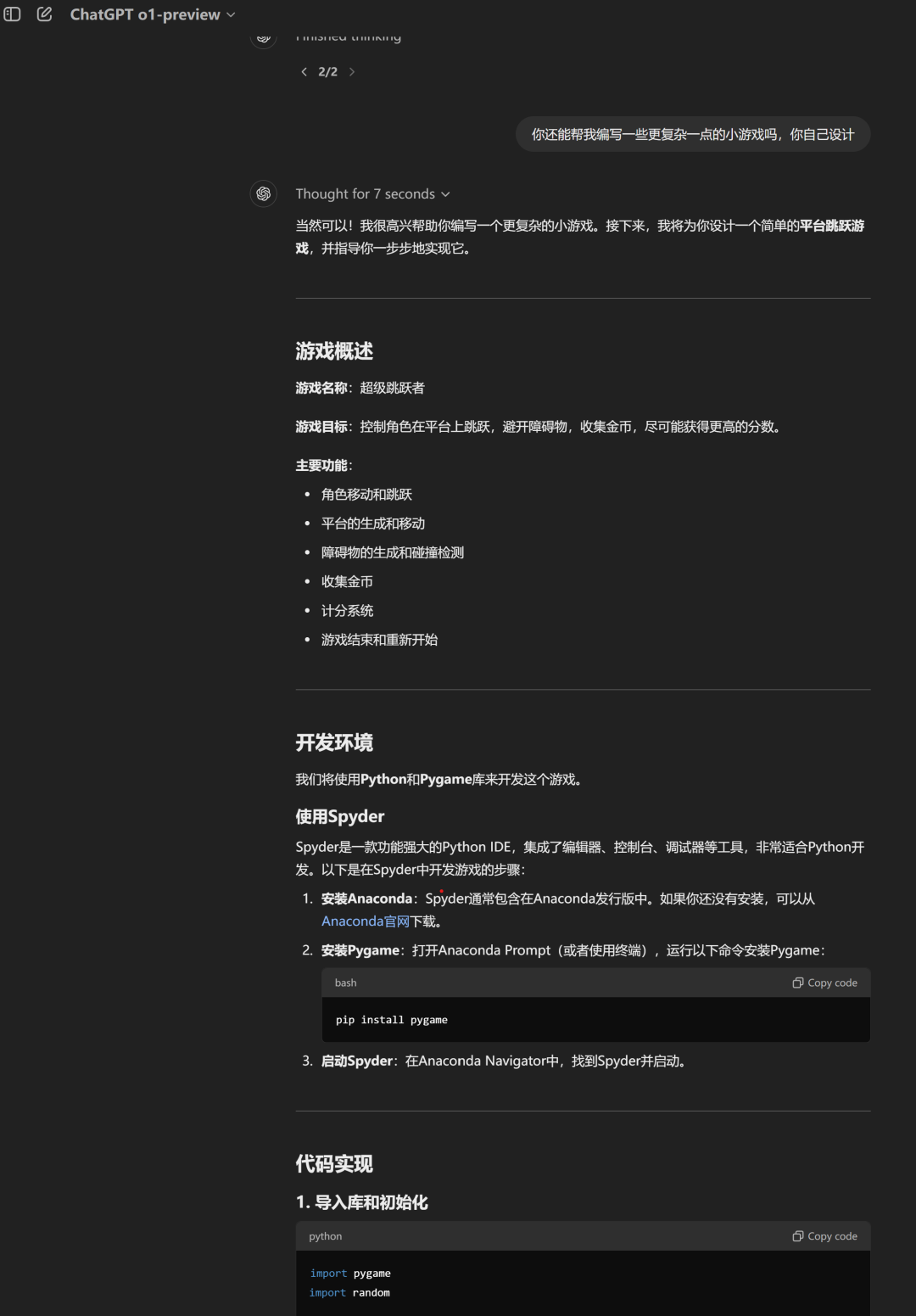
4)科學類測試
在科學類測試方面,記者重點測試了o1-preview在數學和經濟學上的表現。
首先,記者拋出的是一個數學推理問題,向o1-preview詢問解決歐拉方程有限時間爆破的可能方法(這是著名華裔數學家、菲爾茲獎得主陶哲軒教授本周才發表的討論文章)。
o1雖然沒有給出明確解法,但卻提供了一個解題思路,這一思路和陶哲軒教授文章部分吻合(雖然很少)。

經濟學方向上,記者向o1-preview詢問了一個復雜的經濟系統問題。從給出的反饋看,基本沒有什么太大的問題,整體邏輯清晰,思考維度也是多樣化的,給出的數學公式雖然有一點小差錯但是無傷大體。

5)事實性知識與語言理解
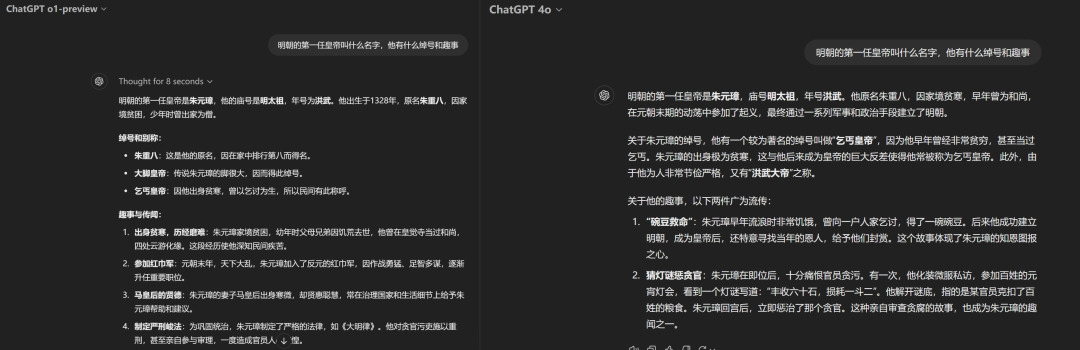
在這一環節,記者向o1-preview詢問了明朝第一任皇帝的趣事,但o1就將趣事理解成了歷史上實際發生過的事情,將朱元璋的歷史故事整個敘述了出來。
同時,記者也將這一問題丟給了GPT-4o模型,作為對比,GPT-4o能很好地理解記者的問題,并講了兩個流傳很廣的民間小故事。
總體來看,OpenAI宣稱o1模型能接近人類水平在某些方面上看起來并不是虛話。
最讓記者驚喜的是,OpenAI將模型思考的過程用文字展示給了用戶,文字思考過程中,大模型大量使用了“我正在”“我認為”“我打算”等話語,感覺更加擬人化,就像一個真人在用戶面前闡述自己的思考邏輯一般。

但這也并不意味著o1模型就是完美的。OpenAI也承認,在設計、寫作、編輯文字等方面上,o1遠不如GPT-4o。o1也沒有瀏覽網頁或處理文件和圖像的能力。
而最讓記者感到頭疼的是,即使是一個很簡單的請求,比如說將輸出結果轉換為中文,o1都會消耗十幾秒鐘的時間來思考,而GPT4o就會很快處理好這一請求。
就算在OpenAI的優勢領域中,o1模型也會突然出現性能下降,模型輸出懶惰的情況。已離職的OpenAI創始人Karpathy就吐槽道:“它一直拒絕為我解決黎曼假說。模型懶惰仍然是一個主要問題。”
OpenAI表示,公司會在之后的更新中解決這些問題,畢竟現在這只是推理模型的早期預覽。
記者|鄭雨航?岳楚鵬(實習)
編輯|程鵬?蘭素英?杜恒峰
校對|劉小英
 |每日經濟新聞 ?nbdnews??原創文章|
|每日經濟新聞 ?nbdnews??原創文章|
未經許可禁止轉載、摘編、復制及鏡像等使用
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













