每日經濟新聞 2024-11-06 14:30:42
◎ 清華大學交叉信息研究院研究團隊發現,“數據規模法則”也適用于機器人領域。該團隊的研究表明,只要有足夠的數據,機器人就能像ChatGPT理解語言一樣,自然地理解和適應物理世界。針對這項最新研究,《每日經濟新聞》記者專訪了該研究論文的作者之一胡英東。
每經記者 蔡鼎 每經編輯 蘭素英
如果將人工智能(AI)比作孩子,那么Scaling Law(以下簡稱“規模法則”)就是其重要的“成長密碼”:只要“孩子”被給予足夠的“營養”,即數據、模型和算力,他就能茁壯成長。
2020年,OpenAI發表論文《神經語言模型的規模法則》(Scaling Laws for Neural Language Models),提出“規模法則”,為大語言模型的出現奠定了語言基礎。因此“規模法則”也被視為人工智能的基石。
如今,這一的“規模法則”也正在引領機器人領域開啟新世界的大門。

來源:《機器人操作模仿學習中的數據規模法則》論文
清華大學交叉信息研究院(以下簡稱IIIS)研究團隊近日在預印本網站arXiv發布的論文《機器人操作模仿學習中的數據規模法則》(Data Scaling Laws in Imitation Learning for Robotic Manipulation)顯示,在“數據規模法則”下,機器人實現了真正的零樣本泛化,無須進行任何微調就能泛化到全新的場景和物體,成功率高達90%。所謂泛化,指的是一個模型或算法在處理未曾見過的新數據時的表現能力。
團隊的發現表明,只要有足夠的數據,機器人就能像ChatGPT理解語言一樣,自然地理解和適應物理世界。一時間,外界對人形機器人可能迎來“ChatGPT時刻”議論紛紛。
連Google DeepMind的機器人專家Ted Xiao都稱,其對機器人大模型時代具有里程碑意義。

圖片來源:X平臺
針對這項最新研究,《每日經濟新聞》記者于11月4日晚間專訪了該論文的作者之一、清華大學IIIS四年級博士生胡英東。
胡英東博士重點研究嵌入式AI,這是機器學習、機器人和計算機視覺交叉的前沿領域。他研究了開發通用機器人系統的基本挑戰,這些系統可以有效適應和概括他們在不同的、非結構化的現實世界環境中的學習行為。

胡英東 圖片來源:預印本網站arXiv
火鍋店倒水、公園疊毛巾、電梯內拔插頭……在清華大學IIIS研究團隊最新進行的研究中,便攜式手持夾爪UMI在8種從未見過的環境中展現出來超強的適應能力。

IIIS團隊機器人硬件設置 圖片來源:《機器人操作模仿學習中的數據規模法則》論文截圖

研究設計的任務 圖片來源:《機器人操作模仿學習中的數據規模法則》論文截圖
ChatGPT的問世驗證了“規模法則”的“智能涌現”能力——規模越大,效果越優。要提升模型效果,就需要不斷擴大參數規模、訓練數據量、計算資源的規模。但機器人領域尚未建立全面的“規模法則”,因而未能取得深度學習領域那么快的發展。
為了探究上述三大要素之一——“數據規模法則”,清華大學IIIS研究團隊設計了物體泛化、環境泛化及環境-物體組合泛化三大維度,通過系統調整訓練數據規模,全面評估適當的數據規模能否產生可在任何環境下對幾乎任何物體進行操作的機器人策略。
利用真實環境下收集的超過4萬條人類演示數據,以及嚴格評估協議下進行的超15000次實機測試,該團隊發現,策略的泛化性能與環境和訓練時接觸的物體數量呈現顯著的冪律關系,意思是其中一個量的相對變化會導致另一個量的相應冪次比例的變化,且與初值無關。
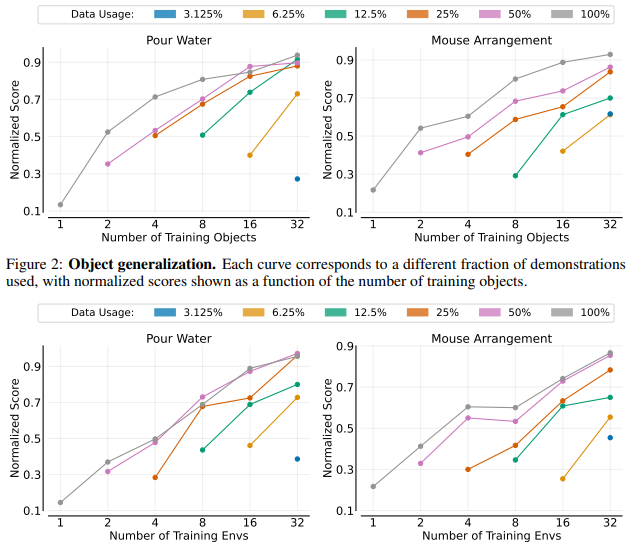
圖片來源:《機器人操作模仿學習中的數據規模法則》論文截圖
而且,當環境多樣性足夠豐富時,在單一環境中過度采集不同操作物體的數據所帶來的效用將變得微乎其微。而且,單個物體的演示數據很容易達到飽和,總演示數據達到800次時,性能就開始趨于穩定。該團隊認為,每個物體有50次演示效果就基本能達到期望的泛化水平了。
最終的任務測試表明,在8種全新的場景中,機器人的成功率高達90%。這意味著機器人實現了真正的零樣本泛化,可以無須進行任何微調就能泛化到全新的場景和物體。
也就是說,團隊的發現表明,只要有足夠的數據,機器人就能像 ChatGPT 理解語言一樣,自然地理解和適應物理世界!而且,這也簡化了數據收集工作,以前可能需要幾個月才能完成,現在只需要幾天甚至一個下午。
NBD:您能否分享一下,是什么促使團隊去探索具身智能領域的“數據規模法則”?是否受到了大語言模型“規模法則”的影響?
胡英東:是的,我們對“數據規模法則”的探索確實部分受到大語言模型的啟發。大模型中“規模法則”已經成為當今最基本的原則之一,它包括三個維度:數據、模型和算力。在探索模型和計算“規模法則”之前,理解“數據規模法則”是至關重要的。
NBD:能否用通俗的語言解釋一下“數據規模法則”?
胡英東:我們發現,“數據規模法則”展示了機器人策略在新環境中的性能與訓練中的環境和物體數量之間的冪律關系。簡單地說,訓練中包含的環境和物體數量越多,泛化性能越好。
NBD:論文中提到,“提高數據質量可能比盲目增加數據量更重要”。那么,您認為如何才能有效地提高數據質量呢?是否有具體的方法或策略?
胡英東:數據質量有很多方面,但我們主要關注數據的多樣性。我們發現,在資源有限的情況下,在更廣泛的環境和物體中收集人類演示比在特定環境中使用特定物體收集更多演示帶來的效果更好。

疊毛巾 來源:《機器人操作模仿學習中的數據規模法則》論文
盡管IIIS團隊的研究表明,只需投入相對較少的時間和資源,就有可能學習到一種可在任何環境和對象中零距離部署的單任務策略。現實中,要完成洗衣服、疊衣服等一些在人類看來非常簡單的任務,AI依然面臨不小的難度。
論文也指出,目前的工作還有一些局限性,他們只關注了單任務策略的數據規模,并沒有探索多任務的通用性,因為這需要從數千個任務中收集數據。除了數據規模,IIIS團隊還在模型規模化方面有三個重要發現:視覺編碼器必須經過預訓練和完整的微調,缺一不可;擴大視覺編碼器的規模能顯著提升性能;擴大擴散模型的規模卻沒能帶來明顯的性能提升,這一現象最讓人意外。
為了激勵更多的研究人員就此進行探索,團隊還公布了其代碼、數據和模型,希望業界能最終開發出能夠解決復雜問題的通用機器人。
IIIS團隊在GitHub上開源的代碼
IIIS團隊在Hugging Face上公布的數據
NBD:你們的研究發現,通過適當的“規模法則”,單任務策略可以應用于任何新環境和同一類別中的任何新對象。這是否意味著一旦機器人掌握了足夠的數據,它們就不需要進一步學習了?
胡英東:這并不意味著機器人不再需要學習。雖然目前有90%的成功率,也讓人印象深刻,但對于商業化和家庭使用仍然不夠,我們需要達到99.9%以上的成功率,畢竟你不會希望一個機器人在倒水的時候有10%的幾率打破你的杯子。
NBD:機器人在學習大量數據后,能夠適應各種環境。這是否預示著未來很可能會出現通用機器人?
胡英東:我相信我們將來會看到通用機器人,我不能準確預測是什么時候。我們的研究只探索了數據規模,正如我之前提到的,我們還沒有完全研究模型和計算規模。仍有許多重要的研究問題需要解決。

來源:《機器人操作模仿學習中的數據規模法則》論文
在學界的努力之外,企業界也在專注于將通用人工智能引入物理世界,旨在開發大規模人工智能模型和算法,為機器人提供動力。
OpenAI就是其中之一。11月4日,Meta增強現實眼鏡“Orion”團隊的負責人凱特林·卡林諾夫斯基在社交媒體上宣布,自己已經加盟OpenAI,領導機器人和消費者硬件團隊。他在帖子中表示,這份新工作最初將關注OpenAI在機器人領域的工作以及相關的合作,幫助AI“進入物理世界”,解鎖對人類的好處。
同日,OpenAI被曝還參與了機器人AI初創公司Physical Intelligence的4億美元融資輪。本輪融資由亞馬遜創始人Jeff Bezos、Thrive Capital和Lux Capital領投。
Physical Intelligence在博客文章中提到,過去八個月里,他們一直在為機器人開發一種“通用”的人工智能模型。Physical Intelligence希望這個模型能成為他們實現最終目標——開發人工通用智能(AGI)的第一步。AGI是指在各種任務上達到或超越人類智能的人工智能技術。
NBD:一些文章將你們最新的研究發現稱為“人形機器人的ChatGPT時刻”,您對此有何看法?你認為這個時刻是否已經到來,還是需要更多的技術突破?
胡英東:我并不認為我們已經達到了“人形機器人的ChatGPT時刻”,盡管我們正在朝著這個目標快速前進。ChatGPT的一個關鍵特征是其非凡的泛化能力——它能夠在幾乎任何用戶定義的任務中表現良好。雖然我們強調機器人對新環境和新物體的泛化能力,但主要的區別在于我們的模型還不是真正通用的,不能處理用戶可能給出的各種各樣的指令。
NBD:研究已經在多個現實場景中得到了驗證,那么您認為這些實驗結果有一天能轉化為實際應用嗎?
胡英東:我相信我們研究的這項技術最終會進入日常實際應用,例如,用于餐館的服務機器人。更有意義的是,這樣的機器人可以應用于養老院,以協助老年人護理,這將是特別有價值和影響的。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














