每日經濟新聞 2024-11-13 23:07:55
每經記者 王嘉琦 每經實習記者 宋欣悅 每經編輯 蘭素英

一、評測場景與參評模型概述
2024年6月25日,《每日經濟新聞大模型評測報告》第1期發布,對15款市面主流大模型在“財經新聞標題創作”“微博新聞寫作”“文章差錯校對”“財務數據計算與分析”四個新聞采編應用場景的能力進行了評測。
2024年9月6日,《每日經濟新聞大模型評測報告》第2期發布,重點考察大模型在“金融數學計算”“商務文本翻譯”“財經新聞閱讀”三個新聞采編應用場景的能力。
與前兩期評測一樣,《每日經濟新聞大模型年度評測報告》繼續以大模型在新聞采編場景的應用能力為評測目標,但為了更精準對接采編人員的實際需求,本次評測以“采寫編審和短視頻創作的新聞生產全流程”為場景,包括大模型設計采訪提綱——撰寫新聞稿件——校對稿件差錯——提煉稿件標題——改寫短視頻文本五個細分場景。通過大模型在新聞生產全流程的介入,評測出“誰是新聞生產全流程的最優秀大模型”,用直觀的評測結果,對采編人員在工作中選用適合的大模型工具提供實戰參考。
本次評測設置的五個細分應用場景具體如下:
(1)設計采訪提綱:旨在考察大模型能否幫助記者擬定采訪提綱,輔助記者采訪工作。
(2)撰寫新聞稿件:旨在考察大模型圍繞既定的多份材料,能否創作一篇新聞稿件。
(3)校對稿件差錯:旨在考察大模型能否檢查出新聞稿件中的錯別字,語法、數字、標點符號等差錯。
(4)提煉稿件標題:旨在考察大模型能否根據稿件內容,提煉新聞標題,特別是制作適合在微信等新媒體平臺傳播的新媒體風格標題。
(5)改寫短視頻文本:旨在考察大模型能否根據一篇文字新聞稿件,改寫成適合短視頻發布的文案。
每經大模型評測小組為五個細分場景制定了對應的評價維度和評分指標。每日經濟新聞10余名首席、高級、資深記者編輯根據評價維度和評分指標,對各款大模型在五個細分場景中的表現進行評分,匯總各場景得分,最終得到參評大模型總分。
需要指出的是,本期評測是通過各款大模型的API端口,并在默認溫度下完成。與公眾用戶使用的大模型C端對話工具存在差異。但是評測結果對用戶在具體場景中選擇合適的大模型工具,依然具有重要參考價值。
本期評測均在“雨燕智宣AI創作+”測試臺上進行,一共有12款國內大模型參與。
評測時間為2024年10月18日,因此參評大模型均為截至10月18日的最新版本。

二、評測結果
評測結果顯示,騰訊混元hunyuan-turbo以379.53的總分位居榜首,緊隨其后的是智譜GLM-4-Plus獲得368.6分,字節跳動doubao-pro-32k(240828版本)獲得363分。
在五個細分場景方面,各家模型展現出不同的優勢:
在設計采訪提綱場景中,騰訊混元hunyuan-turbo與昆侖萬維天工SkyChat-3.0兩款模型均取得了93.33分的佳績,并列第一。
在撰寫新聞稿件場景中,智譜GLM-4-Plus以98分的高分拔得頭籌。
在校對稿件差錯場景中,智譜GLM-4-Plus以60分的成績位居首位。
在提煉稿件標題方面,深度求索DeepSeek-V2.5模型以55.2分的成績領先其他模型。
在改寫短視頻文本場景中,騰訊混元hunyuan-turbo再次展現其強勁實力,以95分的成績位列第一。

1、評測場景一:設計采訪提綱
(1)評測任務
采訪是新聞生產的基礎,需要記者進行大量的前期準備工作,包括收集采訪資料、確定采訪主題等。而設計采訪提綱是將各項準備工作進行“集合式”整理,是記者綜合能力和思考能力的體現。
本期評測的第一個場景“設計采訪提綱”旨在檢驗各款大模型在構建采訪結構,設計有深度的采訪問題以及挖掘、分析信息方面的能力。
為此,評測小組首先針對采訪對象收集了詳盡的背景資料,接著要求大模型根據這些已有的背景資料,設計一份包含5個采訪問題的采訪提綱。
(2)評測結果
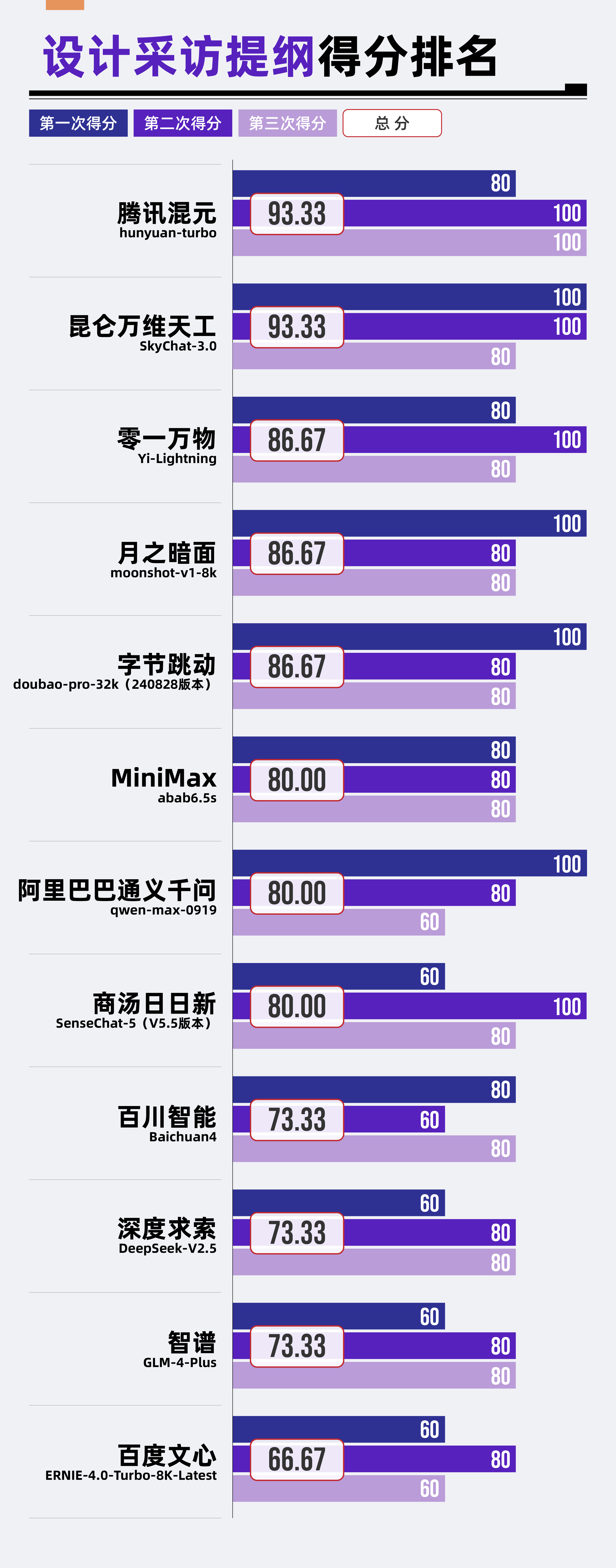
(3)結果分析
從整體結果來看,參評大模型在“設計采訪提綱”場景中表現頗為出色。在12款大模型中,有8款模型的得分不低于80分,展現出較高的水平。
其中,騰訊混元hunyuan-turbo和昆侖萬維天工SkyChat-3.0以93.33分的高分并列第一,零一萬物Yi-Lightning、月之暗面moonshot-v1-8k、字節跳動doubao-pro-32k(240828版本)緊隨其后,均展現出了不俗的實力。
然而,百度文心ERNIE-4.0-Turbo-8K-Latest在該場景下的表現則稍顯遜色,位于榜單的最末位。
2、評測場景二:撰寫新聞稿件
(1)評測任務
本次評測的第二個場景選擇了“撰寫新聞稿件”,旨在評估參評大模型是否能高效生成符合新聞專業標準的稿件內容。
評測小組向大模型提供了新聞寫作主題、方向以及相關素材,并要求大模型根據要求和相關資料,撰寫一篇完整的新聞稿件。
(2)評測結果
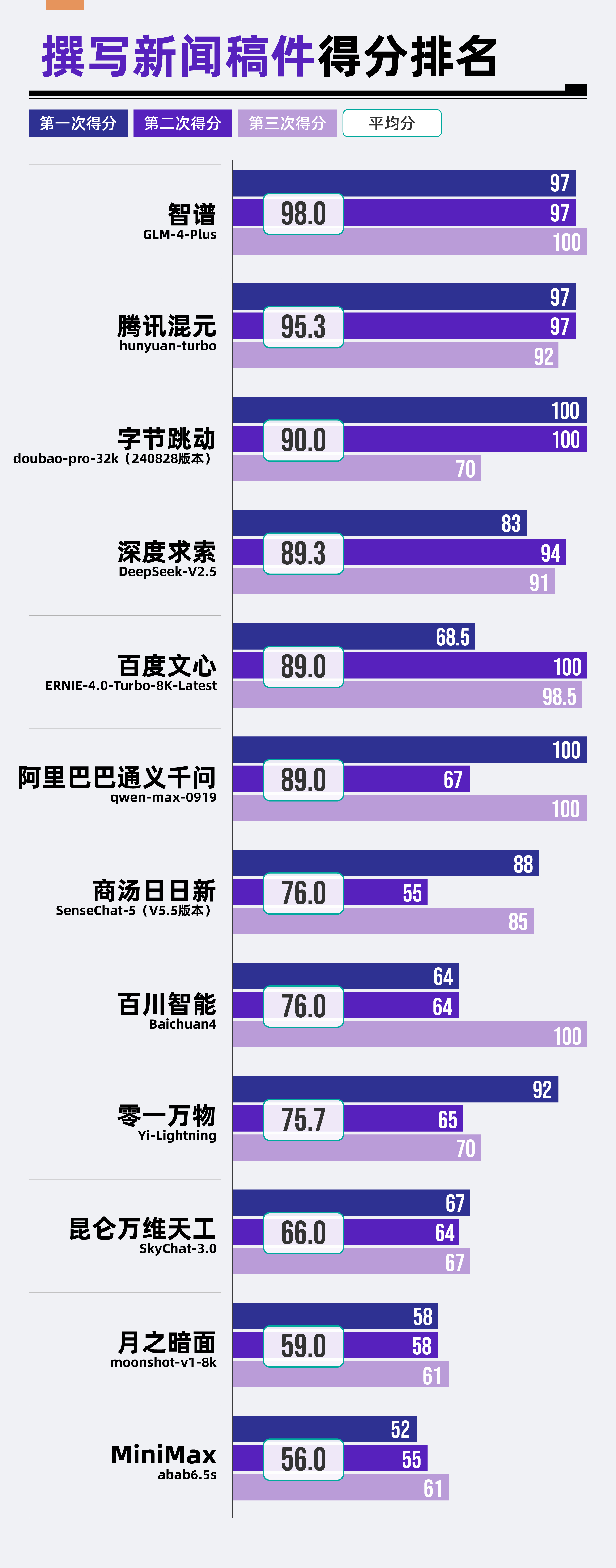
(3)結果分析
在撰寫新聞稿件場景中,智譜GLM-4-Plus以總分98分的成績排名第一。騰訊混元hunyuan-turbo、字節跳動doubao-pro-32k(240828版本)、深度求索DeepSeek-V2.5三款大模型緊隨其后。相比之下,昆侖萬維天工SkyChat-3.0、月之暗面moonshot-v1-8k及MiniMax abab6.5s在此方面的表現則稍顯不足,分列該場景排名的后三位。
從各個維度綜合評估,大模型在“新聞要素完整”與“新聞結構規范”兩大方面展現出了卓越的表現,所有參與評測的12款大模型均在這兩項維度上表現優異。
然而,真正使各款模型拉開分數差距的,在于“新聞信息準確”和“新聞要點全面”這兩個維度。
該場景的前兩名智譜GLM-4-Plus和騰訊混元hunyuan-turbo就在“新聞信息準確”維度上,均獲得了滿分,彰顯其在信息篩選與核實上的高水準。相反,“吊車尾”的昆侖萬維天工SkyChat-3.0、月之暗面moonshot-v1-8k以及MiniMax abab6.5s在該維度上的表現不盡如人意,這在一定程度上反映了它們在信息處理能力上的不足。
3、評測場景三:校對稿件差錯
(1)評測任務
“校對稿件差錯”需要對新聞事件進行核實,數據進行校準,并對文字、標點、語句等差錯予以糾正,這是保證新聞稿件質量,出版內容準確不可或缺的一環,關系到新聞媒體的權威性以及公眾對媒體的信任度。
因此,評測小組選擇“校對稿件差錯”作為本期評測的第三個場景,一方面考察大模型對細節的把控能力,另一方面也檢驗大模型結合上下文的分析能力。
評測小組在新聞稿中設置了10處錯誤,包括錯別字、標點符號使用不當、事實和信息不準確等錯誤類型。
(2)評測結果
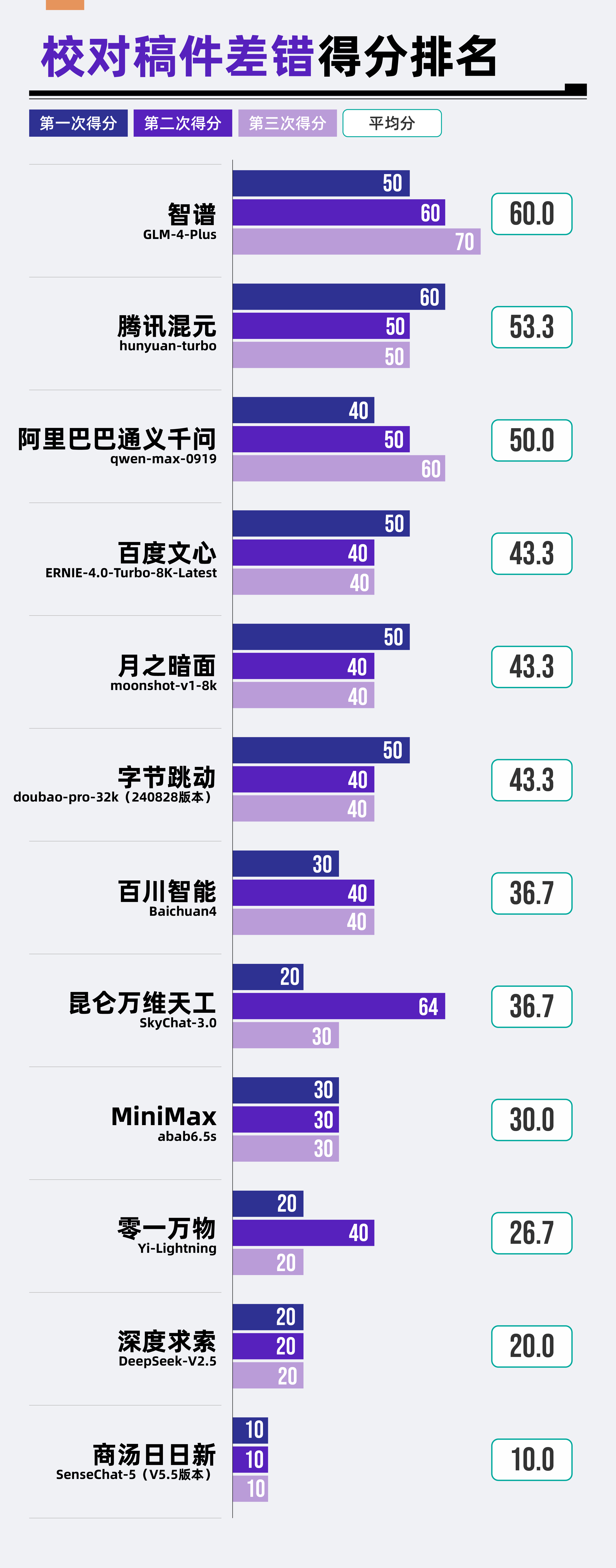
(3)結果分析
從本次評測的整體結果來看,“校對稿件差錯”是本次五個評測場景中大模型表現最為薄弱的一環,總體平均分僅為37.78分,遠低于預期。
從本次評測的在參評的12款大模型中,僅有智譜GLM-4-Plus一款大模型得到了60分的及格線。而零一萬物Yi-Lightning、深度求索DeepSeek-V2.5以及商湯日日新SenseChat-5(V5.5版本)則分列倒數三位。
從具體題目來看,對于錯別字、語法、數據和單位等相對簡單的差錯,多數大模型能夠校對出來,并進行相應的糾正。但對于需要聯系上下文,進行一定邏輯分析的新聞事實差錯,大模型的校對能力還要亟待提升。
評測小組一共設置了3處事實和信息錯誤,遺憾的是,其中有2處錯誤讓12款大模型集體“翻車”。在這兩處錯誤上,沒有一款大模型能夠成功校對并予以糾正。
另外,評測小組還發現,參評大模型往往還會對一些原本正確的新聞內容給出錯誤的判斷。
4、評測場景四:提煉新聞標題
(1)評測任務
新聞標題通過精煉的文字和巧妙的修辭手法,吸引讀者眼球,激發閱讀興趣,是新聞傳播的關鍵。
本期評測的第四個場景“提煉新聞標題”,旨在檢驗大模型能否通過閱讀新聞稿件,準確抓住新聞點和新聞核心內容,并用簡潔的語言,制作出精煉且富于感染力的標題;同時還考察大模型的語言運用能力,能否靈活運用修辭手法和語法結構,保證標題的邏輯性和準確性。
為此,評測小組選取了每日經濟新聞的稿件作為測試樣本,讓大模型圍繞稿件,提煉出符合新媒體傳播的微信標題。
(2)評測結果
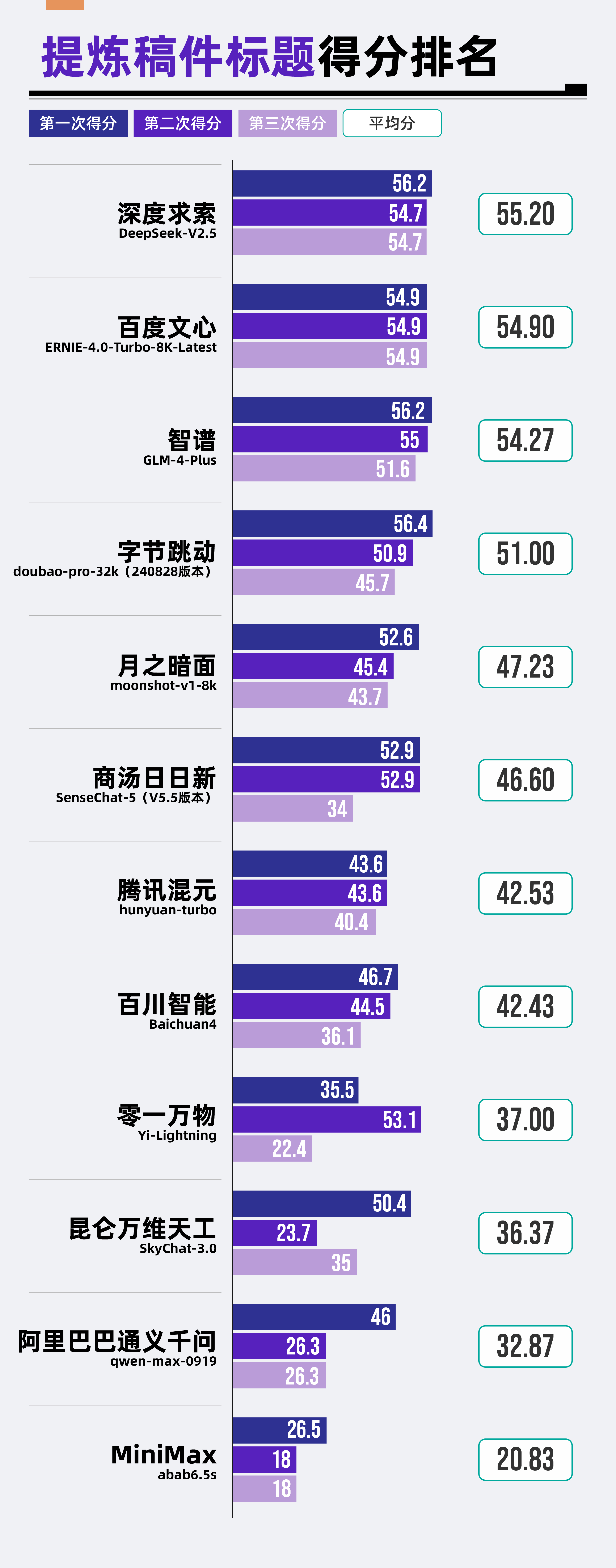
(3)結果分析
從整體結果來看,參評12款大模型中,沒有一款能夠達到60分的及格標準,平均分僅為43.44分,整體水平有待提升。
其中,深度求索DeepSeek-V2.5以55.2分的成績位居榜首;百度文心ERNIE-4.0-Turbo-8K-Latest則以54.9分的微弱差距緊隨其后,位列第二。這兩款模型的表現相對突出,但仍未達到滿意的水平。
而排名后三位的大模型昆侖萬維天工SkyChat-3.0、阿里巴巴通義千問qwen-max-0919以及MiniMax abab6.5s表現則更加不盡如人意,得分分別為36.37分、32.87分和20.83分。
另外,值得注意的是,零一萬物Yi-Lightning和昆侖萬維天工SkyChat-3.0兩款大模型在生成微信新聞標題時存在準確性和穩定性方面的問題,需要進一步優化和改進。在三次結果生成過程中,零一萬物Yi-Lightning有兩次出現了新聞標題的錯誤,而昆侖萬維天工SkyChat-3.0也出現了一次錯誤。準確性是新聞報道的基本原則,而標題作為新聞稿件的“窗口”和“眼睛”更是不能出現任何差錯。
評測小組發現,大模型整體得分偏低的主要原因,在于其生成的標題缺乏亮點,未能有效抓住稿件的新聞點或稿件中最具吸引力的內容,所以提煉的標題難以吸引讀者眼球。此外,多個大模型生成的新聞標題中頻繁出現一些過于“高大上”的抽象概念詞匯,這不僅使得標題顯得空洞而寬泛,還無形中增加了與讀者之間的隔閡,進而削弱了讀者閱讀稿件的興趣。
5、評測場景五:改寫短視頻文案
(1)評測任務
視頻文案無疑是短視頻的靈魂所在。好的短視頻文案,能夠通過精準而富有吸引力的文字,迅速抓住觀眾的注意力,引導觀眾深入了解短視頻的詳細內容,從而提升完播率。
本期評測的最后一個場景為“改寫短視頻文案”,這一場景旨在考察大模型在短視頻文案創作中對信息的快速提煉,以及適應短視頻平臺風格的能力。
評測小組要求各款大模型把一篇文字新聞稿件,改寫成語言精煉、觀點明確且吸引觀眾的短視頻文案。
(2)評測結果
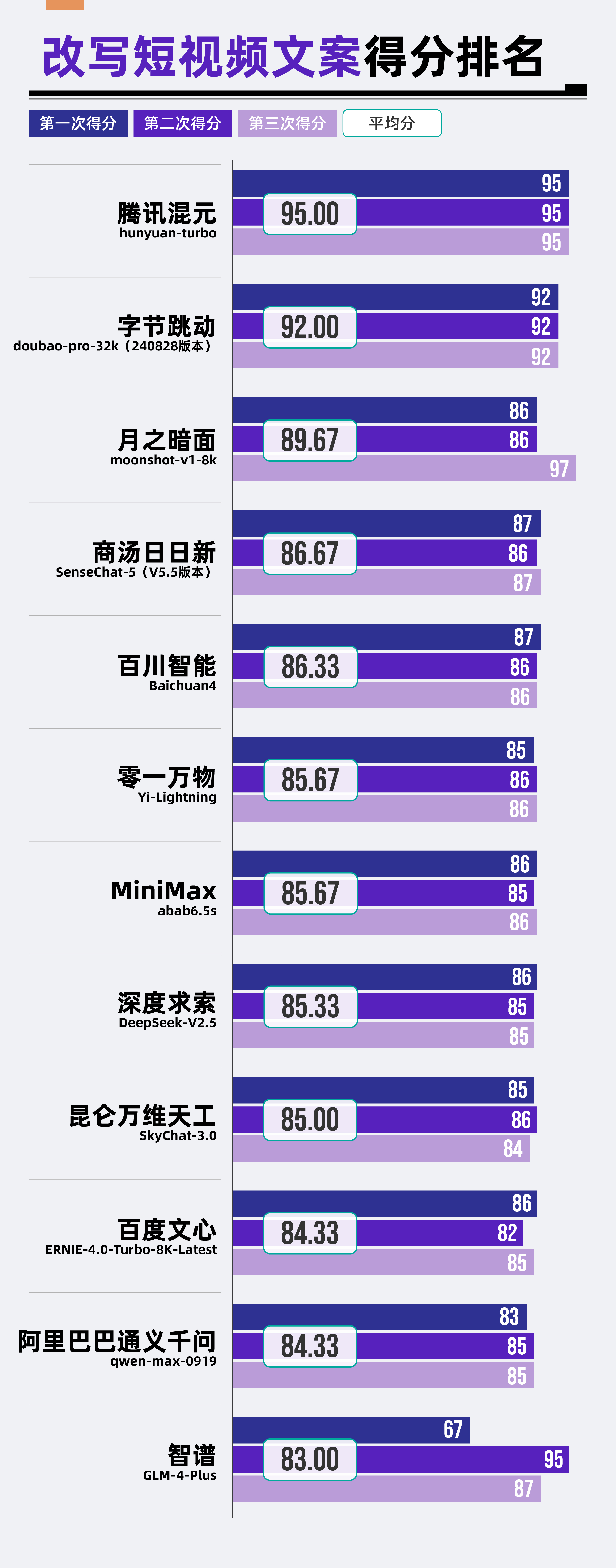
(3)結果分析
從整體評測結果來看,“改寫短視頻文案”是五個評測場景中,大模型表現最為亮眼的一環。在這一場景中,所有參與評測的12款大模型均取得了超過80分的成績,其中,有兩款大模型更是以卓越的表現突破了90分的高分。
具體而言,騰訊混元hunyuan-turbo憑借其出色的實力,以95分的優異成績穩居榜首;而字節跳動doubao-pro-32k(240828版本)也不甘示弱,以92分的佳績緊隨其后,展現出強勁的競爭實力。
騰訊混元hunyuan-turbo和字節跳動doubao-pro-32k(240828版本)的優異表現可能得益于騰訊和字節跳動這兩大科技巨頭在短視頻領域的深厚積累。作為擁有自己短視頻產品的公司,它們旗下的大模型在改寫短視頻文本方面可能擁有更為豐富的語料訓練和更強的技術能力。
三、評測總結
結論一:暫無一款大模型能高質量完成采編全流程工作
截至目前,每日經濟新聞一共推出三期大模型評測報告,覆蓋12項新聞采編應用場景,但從結果來看,沒有一款大模型能在所有場景中均排名前列。
正如人類一樣,各款大模型的長處與短板各不相同。比如,有的大模型擅長財務數據計算,但在新聞標題提煉中卻排名末尾;有的大模型擅長英譯漢,卻在漢譯英方面能力平平。
在新聞生產的關鍵環節,如本期評測中的“撰寫新聞稿件”“校對稿件差錯”“提煉新聞標題”、第一期評測中的“財務數據計算與分析”和第二期評測中的“金融數學計算”等應用場景,多數大模型生成結果的差錯頻出,要保證新聞稿件的高質量、無差錯,還必須由人工審核、把關。
目前市面上還沒有一款大模型能夠高質量、全流程完成新聞采編場景的所有工作,換句話說,世界上還沒有“AI記者”。
結論二:大模型“幻覺”未解,錯誤更隱蔽
盡管各款大模型已經多次迭代升級,但依然解決不了“一本正經地胡說八道”的幻覺問題。
最初的大模型“幻覺”問題比較明顯。隨著產品不斷迭代,大模型生成文本質量逐漸提升,但文本中的錯誤也越發隱蔽。比如,在“撰寫新聞稿件”場景中,大模型會在不起眼處改變人物的職位或虛構事件發生的時間。例如在本期評測中,部分大模型將9月24日“星巴克咖啡公司宣布調整其中國領導層結構”的時間,誤寫成9月30日。再比如在第二期評測“金融數學計算”場景中,即便是得分第一的大模型也會在個別題目中給出了正確的計算公式,卻依然得出錯誤的答案。
對于一篇高質量新聞稿件來說,上述問題都可能是“致命”的差錯。目前,AI生成內容已經大規模出現在互聯網中。這就要求新聞媒體要進一步完善新聞內容真實性審核機制,更需要加強內容把關。
結論三:“冷面”的大模型難判斷新聞價值
閱讀一篇稿件,挖掘出最重要的新聞點,然后提煉和制作標題,在這方面,大模型與經驗豐富的編輯相比,差距不小。
在本期評測的“提煉稿件標題”場景中,大模型得分普遍偏低。其生成的標題多顯得中規中矩。在本期評測的“提煉稿件標題”場景中,大模型得分普遍偏低。其生成的標題多顯得中規中矩。例如大模型提煉的《“星巴克中國新篇章:80后劉文娟接任CEO,引領咖啡巨頭迎挑戰”》《“星巴克中國換帥:80后劉文娟接棒CEO,直面市場挑戰與變革”》等標題。
另外,評測中發現,大模型提煉的新聞標題,往往充斥著一些“高大上”的抽象概念詞匯,無法挖掘文章中最重要的新聞點和有價值的信息,文字空洞,很難吸引讀者的眼球。
此外,在“撰寫新聞稿件”場景中,大模型生成的文本較為生硬,“機器痕跡”較明顯,缺乏情感和個性化的表達。
從現階段來看,大模型在閱讀文章方面,難以具備對一篇稿件新聞點的準確和深層次把握,容易停留在淺層次的理解。因此,新聞點和新聞價值的判斷,包括采寫有溫度、有故事、有人情味的厚重稿件,仍然離不開記者、編輯的人工介入和悉心打磨。
結論四:不同采編場景選擇最適合的大模型
三期大模型評測的場景基本可以分為輔助性場景(如財經新聞閱讀、文本翻譯、設計采訪提綱等)和關鍵性場景(如撰寫新聞稿件、校對稿件差錯、提煉新聞標題等)。
三期評測的結果表明,絕大部分大模型在設計采訪提綱、改寫短視頻文案、英漢翻譯、文章閱讀以及微博新聞寫作等輔助性場景中普遍表現良好。例如,“改寫短視頻文案”場景中,所有參與評測的12款大模型均取得超過80分的成績;而“設計采訪提綱”場景中,有8款大模型的得分高于80分。在第二期評測的“商務本文翻譯”場景中,13款大模型得分都高于80分,在“財經新聞閱讀”場景中,13款大模型得分高于70分。
而在撰寫新聞稿件、校對稿件差錯、提煉新聞標題等新聞生產關鍵性場景的能力則明顯不足。比如,在“校對稿件差錯”場景中,僅一款大模型得分達到60分。在“提煉新聞標題”場景中,沒有一款大模型得分達到60分。
因此,記者、編輯可以根據采編工作的不同環節,不同場景,選擇最適合的大模型,讓部分場景實現采編工作AI化,提升工作效率。
結論五:新聞媒體主導:打造垂直領域的“AI記者”
對比三期大模型評測結果不難發現,國內大模型通過持續迭代,能力穩步提升。同時,各家大模型之間的差距也在逐步縮小,每個模型都展現出獨特的優勢。但這些大模型都屬于通用大模型,并非為新聞媒體、采編工作量身定制。
造成大模型“幻覺”問題嚴重的一大原因,在于訓練文本和數據質量不高,其中包含不少信息錯誤。而新聞工作對準確性要求極高。這一短板直接限制了大模型在新聞領域的應用。然而,新聞媒體在長期的新聞報道中已經積累的大量高質量新聞稿件和數據,這恰恰為研發適合新聞采編工作的大模型工具提供了得天獨厚的土壤。
因此,自主訓練和主導研發大模型工具變得尤為重要,借此,新聞媒體不僅能夠最大限度地確保大模型訓練數據的質量和生成邏輯的準確性,還能保證大模型生成內容的可控性,使其更好地契合媒體自身的屬性和特色。
在研發方法上,可以將采編全流程拆分成數十個環節,如采訪、翻譯、稿件寫作、提煉摘要和校對差錯等。根據各環節的具體工作目標、方法和要求,對大模型進行專項訓練,以形成一系列單任務或垂類AI工具。最終,將這些單任務AI工具打包匯集,則可以打造出一整套新聞采編AI工具。
每日經濟新聞大模型評測小組
2024年11月
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













