每日經濟新聞 2025-01-06 18:42:39
2024年12月26日,AI大模型DeepSeek-V3發布并同步開源,全球刷屏。DeepSeek-V3在聊天機器人競技場中排名第七,是前十名中唯一的開源國產模型,且被評為性價比最高的模型。技術報告揭示其融合了FP8、MLA、MoE三項創新技術,大幅提升了性能和效率。業內人士認為,這些技術的應用標志著實質性突破。
每經記者 鄭雨航 每經實習記者 岳楚鵬 每經編輯 高涵
2024年12月26日,深度求索(DeepSeek)發布了其最新人工智能(AI)大模型DeepSeek-V3,并同步開源,刷屏中外AI圈。DeepSeek在兩年內就成功開發出一款性能比肩國際頂尖的AI模型,成本僅為557萬美元,與OpenAI 7800萬美元的GPT-4訓練成本形成鮮明對比。
聊天機器人競技場(Chatbot Arena)最新數據顯示,DeepSeek-V3排名全模型第七,開源模型第一。競技場官方表示,DeepSeek-V3是全球前十中性價比最高的模型。在風格控制下表現穩健,在復雜問題和代碼領域表現均位列前三。
在長達55頁的技術報告背后,DeepSeek將它的技術路線完整地展示給公眾。有人稱贊它是一次真正的技術突破,但也有人質疑它只是現有優化技術的集成而已,本質上是新瓶裝舊酒。
對此,有業內人士告訴《每日經濟新聞》記者,DeepSeek-V3是首個創新融合使用了FP8、MLA、MoE三項技術的大模型,可以看作是實質性的突破。
最新的聊天機器人競技場(Chatbot Arena)數據顯示,DeepSeek-V3排名第七,成為前十名中唯一的開源國產模型。

圖片來源:聊天機器人競技場
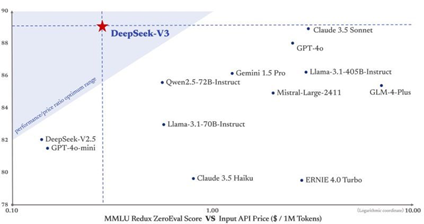
DeepSeek-V3模型被評價為國產第一,并且也是全球前十中性價比最高的模型。DeepSeek-V3在風格控制下表現穩健,在復雜問題和代碼領域沖進了前三名。
聊天機器人競技場是目前最知名的大模型評比榜單,用戶在平臺上同時與兩個匿名模型進行對話,提出相同問題,比較它們的回答。根據模型的回答質量,用戶選擇自己偏好的答案,或選擇平局或都不滿意。根據用戶投票結果,平臺使用Elo評分系統更新模型的分數。相比較于其他基準測試,這一評分標準更能反映出真人用戶對于大模型的偏好。
AI智能體與大語言模型集成平臺Composio也從推理、數學、編程和創意寫作四個維度將DeepSeek-V3和目前最流行的兩個大模型Claude 3.5 Sonnet和GPT-4o進行了比較。
在推理方面,DeepSeek-V3與Claude 3.5 Sonnet、GPT-4o平分秋色,在個別特定問題上還要表現得更好一點。
在數學方面,DeepSeek-V3比Claude 3.5 Sonnet和GPT-4o要好得多。測試者使用了Gilbert Strang的線性代數(MIT的線性代數入門教材)中的一道題作為測試問題。GPT-4o和Claude 3.5 Sonnet都只能找到一個可能的頂點,而DeepSeek-V3能找出三個頂點。
在編程方面,DeepSeek-V3非常接近GPT-4o的編碼能力,但Claude 3.5 Sonnet是表現最好的模型。不過,DeepSeek-V3的定價卻極具吸引力。考慮到性價比,如果只是一般使用的話,Composio認為DeepSeek-V3會是更好的選擇。
在創意寫作方面,Claude 3.5 Sonnet更佳,GPT-4o與DeepSeek-V3相差不大。
但是,DeepSeek現在API的輸入價格僅為每百萬Token0.1元人民幣,而Claude3.5 Sonnet API輸入價格為每百萬Token 3美元。Composio站在使用者的角度判斷,如果用戶想要在大模型之上構建應用程序,那么Deepseek-V3是明智之選。DeepSeek-V3的性價比讓它成為構建面向客戶的AI應用程序的理想選擇。
圖片來源:X
DeepSeek刷屏的另一大焦點便是:它的價格為何那么便宜?
DeepSeek在它長達55頁的技術報告里給出了答案:DeepSeek-V3利用混合專家 (MoE)架構來優化性能,在每次處理過程中僅激活6710億個參數中的370億個。同時還融合使用了多頭潛在注意力(MLA)、FP8混合精度和多token預測等技術進一步提高了其效率和有效性。
有人質疑稱,這些技術在很早之前就已經提出過,DeepSeek只是將這些優化技術集成在一起而已。
對此,資深業內人士、技術交流平臺北京城市開發者社區主理人貓頭虎告訴《每日經濟新聞》記者,DeepSeek-V3有實質突破。他認為,作為首個綜合實力匹敵Meta的Llama3.1-405B的國產開源大模型,DeepSeek-V3創新性地同時使用了FP8、MLA和MoE三種技術手段。
據悉,FP8是一種新的數值表示方式,用于深度學習的計算加速。相比傳統的FP32和FP16,FP8進一步壓縮了數據位數,極大地提升了硬件計算效率。雖然FP8是由英偉達提出的技術,但DeepSeek-V3是全球首家在超大規模模型上驗證了其有效性的模型。
貓頭虎進一步向每經記者表示,這一技術(FP8)至少將顯存消耗降低了30%。
Midjourney的AI研究員Finbarr也表示,Deepseek的FP8設置看上去很棒。
此外,相較于其他模型使用的MoE模型,DeepSeek-V3使用的MoE模型更為精簡有效。該架構使用更具細粒度的專家并將一些專家隔離為共享專家,使得每次只需要占用很小比例的子集專家參數就可以完成計算。這一架構的更新是2024年1月DeepSeek團隊提出的。

圖片來源:arXiv
AI研究人員馬克·貝克在文章中認為DeepSeek的MoE是一個突破性的MoE語言模型架構,它通過創新策略,包括細粒度專家細分和共享專家隔離,實現了比現有MoE架構更高的專家專業化和性能。
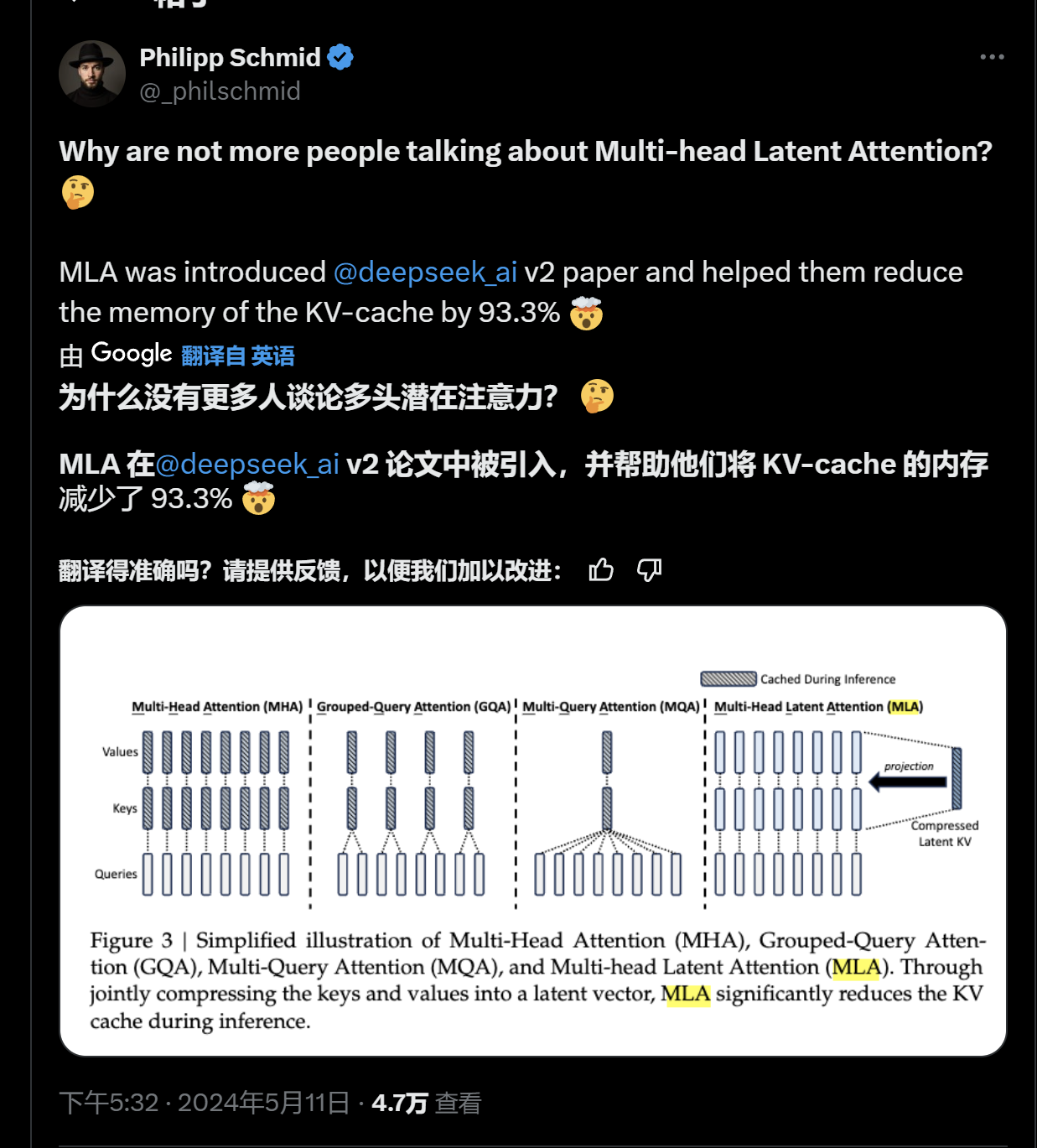
但是最令人驚訝的是MLA機制,這一機制也完全由DeepSeek團隊自主提出,并最早作為核心機制引入了DeepSeek-V2模型上,極大地降低了緩存使用。不過,DeepSeek-V2模型當時并沒有激起什么討論的熱度,只有很少一部分技術人員注意到了這一成果。

圖片來源:arXiv
當時,開源平臺huggingface的技術主管Pjillipp Schmid還在社交平臺上為DeepSeek鳴不平:“為什么沒有更多的人討論MLA(多頭潛在注意力)機制? MLA被引入DeepSeek-V2中,并幫助將KV-cache的內存減少了93.3%。”
編者注:多頭潛在注意力(MLA)是DeepSeek-V2的核心創新,它不僅僅停留在低秩投影的概念上,而是通過更精細的變換設計,實現了在保持推理時KV Cache與GQA相當的同時,增強模型的表達能力。MLA的關鍵在于其推理階段的恒等變換技巧,允許模型在不增加KV Cache大小的情況下,利用不同的投影矩陣增強每個頭的能力。
圖片來源:X
貓頭虎向每經記者表示,FP8、MLA和MoE的融合,是AI技術向更高效率、耕地成本發展的典型案例,尤其在DeepSeek-V3的推動下,這些技術展現出了寬闊的應用前景。
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














