每日經濟新聞 2025-01-21 19:08:09
1月20日,月之暗面推出多模態思考模型Kimi k1.5,DeepSeek開源R1推理模型,雙雙“硬剛”OpenAI。性能測試顯示,這兩款模型在多項測試中能與o1“叫板”。R1更是得到英偉達高級研究科學家Jim Fan等一眾業界大佬的稱贊。不過,R1與開源模型V3一樣,面臨著幻覺問題。
每經記者 岳楚鵬 每經編輯 蘭素英
OpenAI怎么也沒想到,o3還在畫餅階段,中國一夜之間就冒出來兩個能和o1打對臺的模型。
1月20日,月之暗面正式推出多模態思考模型Kimi k1.5,并首次公開該模型的訓練技術報告。
Kimi k1.5在short-CoT(短鏈思考)方面達到領先水平,在其他多個測試中也大幅超越GPT-4和Claude Sonnet 3.5。在Long-CoT(長鏈思考)方面,該模型在多個領域的表現也與o1持平。
同一天,DeepSeek也正式開源R1推理模型,并發布技術報告。R1在多個基準測試中也與o1持平,并且成本只有o1的三十分之一。
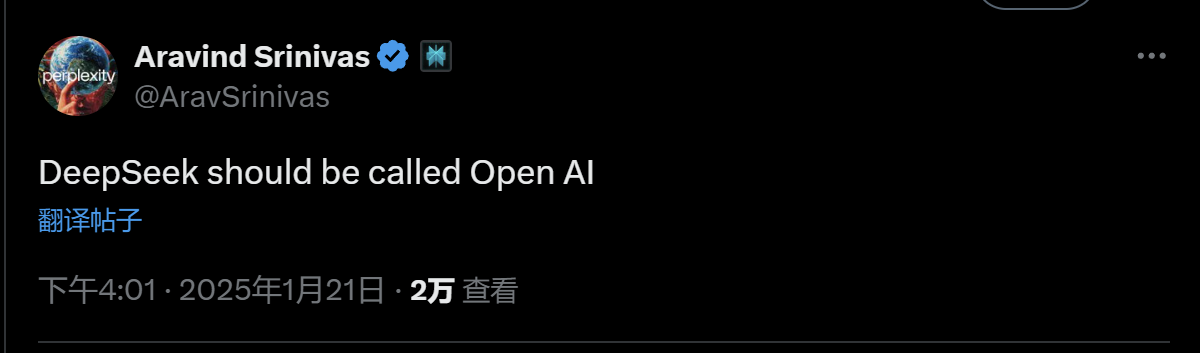
隨著R1模型的開源,英偉達科學家Jim Fan稱:“我們生活在這樣一個時代:由非美國公司保持OpenAI最初的使命——做真正開放的前沿研究、為所有人賦能。”Perplexity CEO Aravind Srinivas表更是直言:“DeepSeek才配叫做OpenAI。”
不過,R1依然面臨著開源模型V3一樣的毛病。有網友向他提問“誰訓練你的”時,它回答道:“我是被OpenAI開發的”。
北京時間1月20日,月之暗面發布了多模態思考模型Kimi k1.5。
在short-CoT模式下,Kimi k1.5的數學、代碼、視覺多模態和通用能力大幅超越了GPT-4o和Claude 3.5 Sonnet,領先幅度高達550%。在Long-CoT模式下,Kimi k1.5的數學、代碼、多模態推理能力達到了OpenAI o1正式版的水平。
月之暗面表示,這應該是全球范圍內,有OpenAI之外的公司首次實現o1正式版的多模態推理性能。
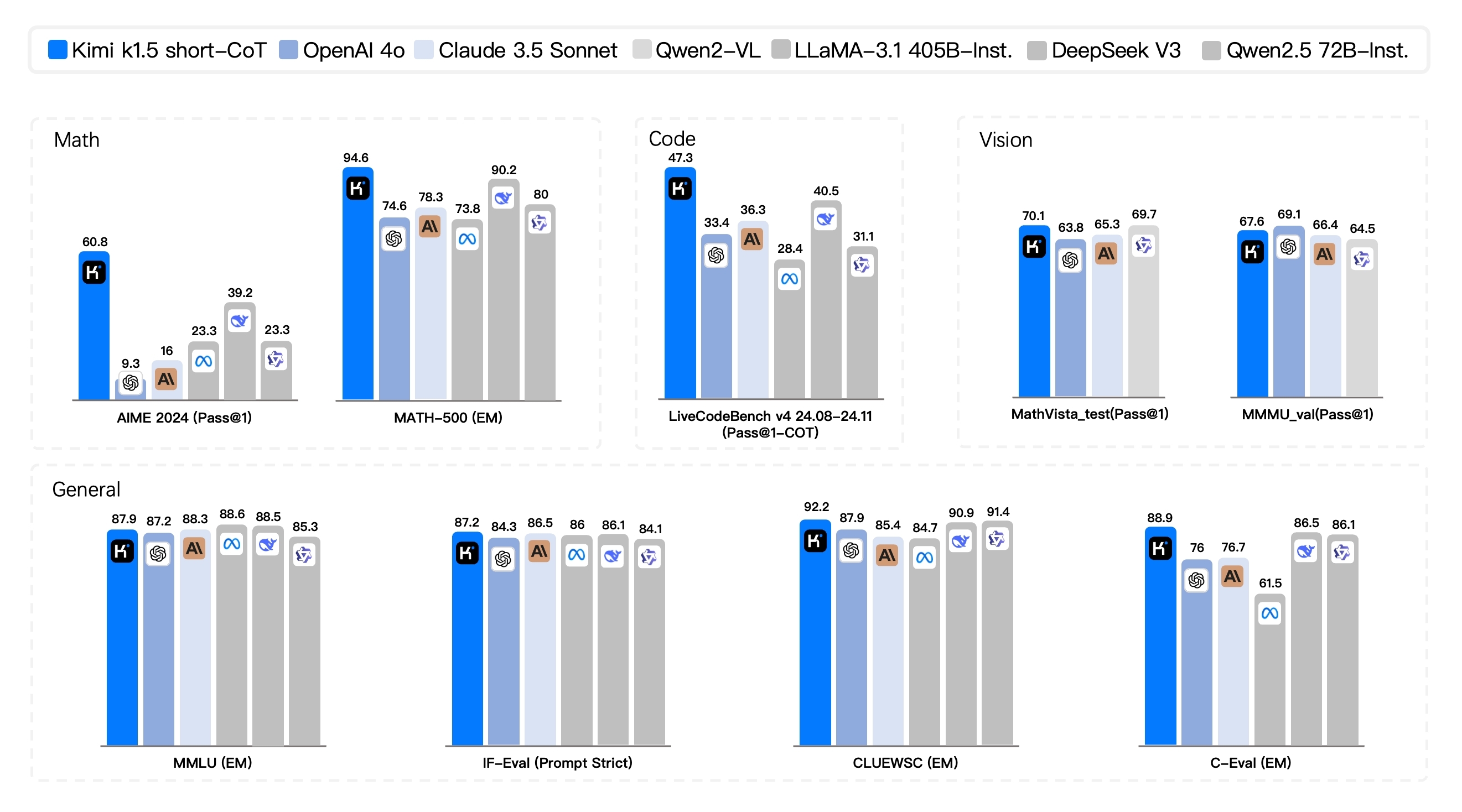

圖片來源:X
同一天,DeepSeek也正式開源R1推理模型,允許所有人在遵循MIT License(注:被廣泛使用的一種軟件許可條款)的情況下,蒸餾R1訓練其他模型。
在數學、代碼和自然語言推理等任務上,R1的性能比肩o1正式版。同時根據DeepSeek公布的測試數據,R1在美國AIME 2024、MATH-500和SWE-bench Verified測試中的比分均高于o1。AIME 2024和MATH-500測試專注于數學能力,SWE-bench Verified則用于評估AI模型解決現實世界軟件問題的能力。
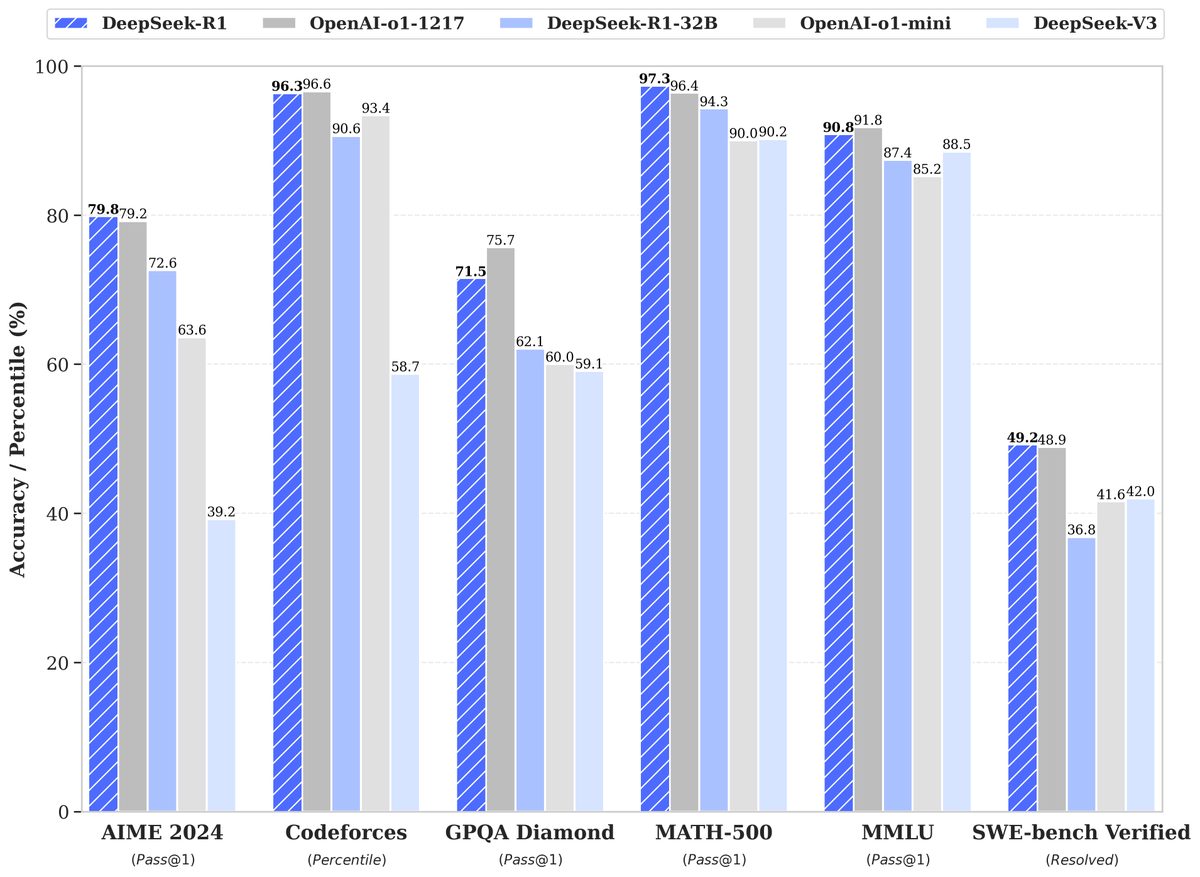
圖片來源:X
更重要的是,R1的價格只有o1的約三十分之一,百萬token輸出只需16元人民幣,相較而言,o1的百萬token輸出需要60美元(約合人民幣436元)。
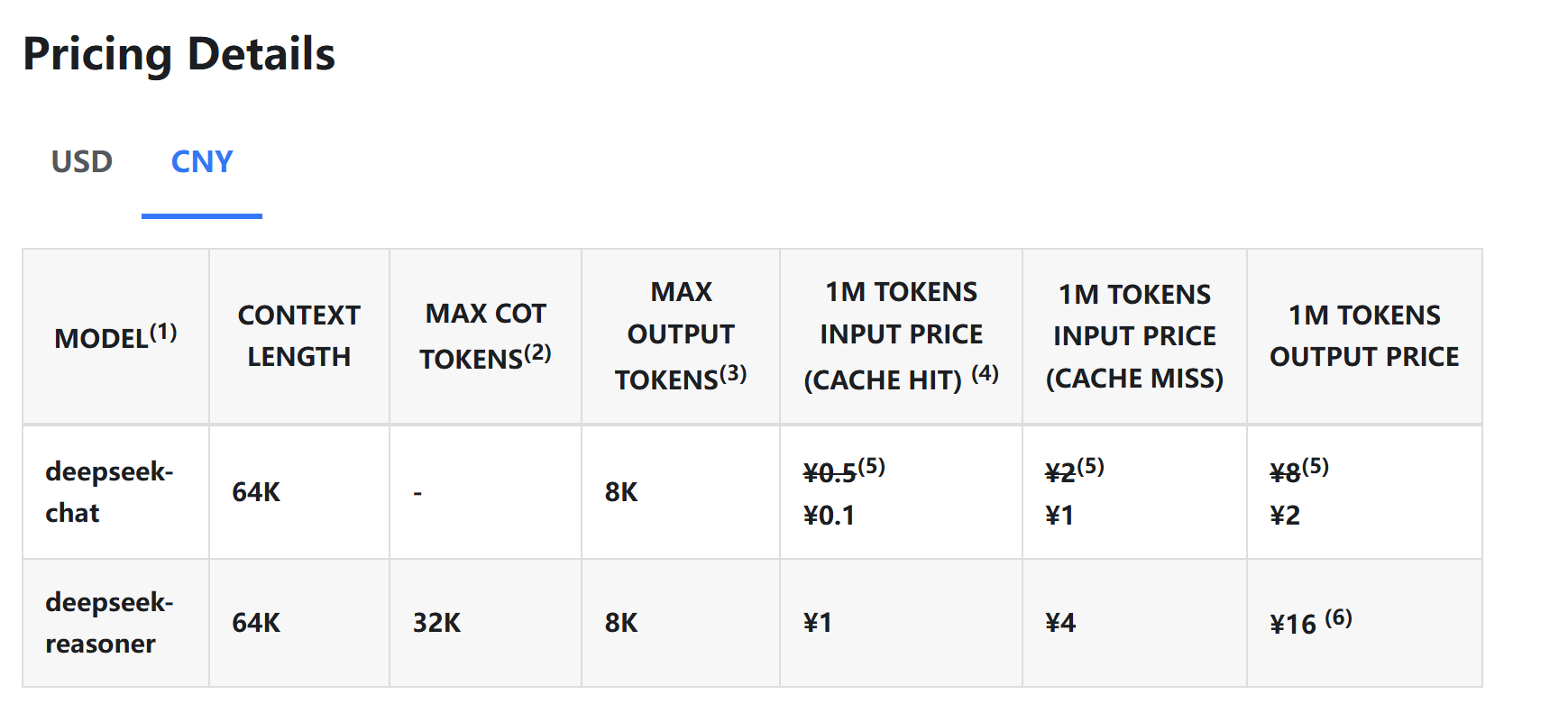
圖片來源:DeepSeek官網
另外,R1的參數量較低,開發人員可以用相對較低的成本在本地運行模型。Exo Lab創始人Alex Cheema在家使用7個MacMini串聯一個MacBook成功運行起了R1模型。他感嘆道:“AGI(通用人工智能)到家了。”
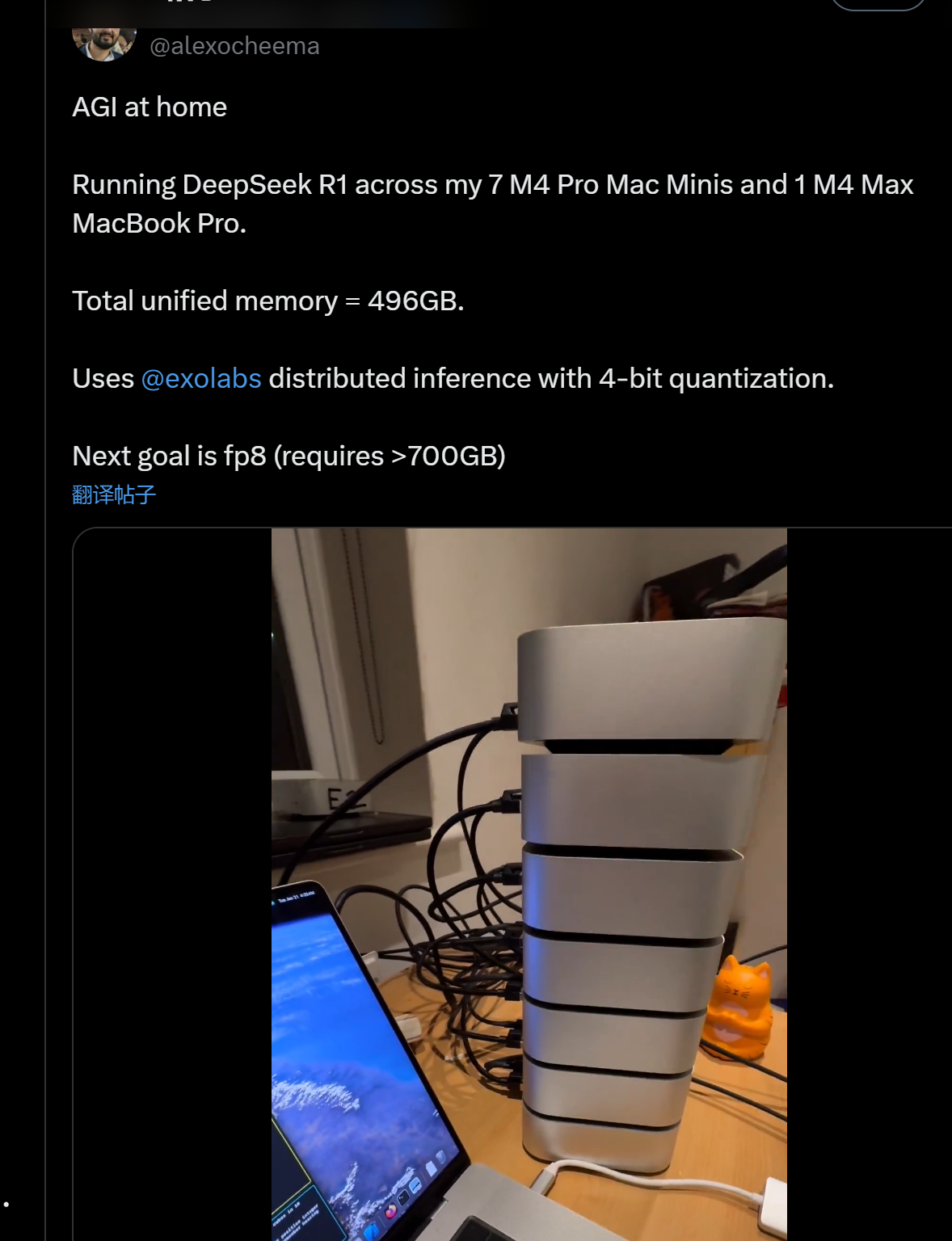
圖片來源:X
R1的技術文檔發布后,英偉達高級研究科學家Jim Fan第一時間對論文進行研究,之后發出了這樣的感慨:“我們生活在這樣一個時代:由非美國公司保持OpenAI最初的使命——做真正開放的前沿研究、為所有人賦能。”
他補充道:“DeepSeek-R1不僅開源了大量模型,還泄露了所有訓練秘密。他們可能是第一個顯示 RL(強化學習)飛輪發揮主要作用、持續增長的OSS項目。(對AI研究的)影響不僅可以通過‘內部實現了ASI’或‘草莓計劃’等神話名稱來實現,也可以通過簡單地轉儲原始算法和matplotlib學習曲線來產生影響。”
Jim Fan的每一句話都在戳喜歡搞神秘,賣期貨的OpenAI的肺管子。

圖片來源:X
實際上,業界有這種看法的人還不少。Abacus ai的CEO Bindu Reddy評價道:“這是開源AGI的勝利,一家來自中國的小型初創公司擊敗了所有人”。
UC Berkeley教授Alex Dimakis也認為,DeepSeek現在已經處于領先位置,美國公司可能需要迎頭趕上了。
Perplexity CEO Aravind Srinivas表更是直言:“DeepSeek才配叫做OpenAI。”
圖片來源:X
除了對OpenAI的諷刺之外,Jim Fan還深入解讀了R1模型的創新之處。
他表示,R1模型純粹由RL驅動,完全沒有SFT(“冷啟動”)。這讓人想起 AlphaZero——從頭開始掌握圍棋、將棋和國際象棋,而無需先模仿人類大師級的動作。
而且,R1使用由硬編碼規則計算的真值獎勵,避免使用任何RL容易攻擊的學習獎勵模型。隨著訓練的進行,模型的思考時間穩步增加。Jim Fan強調,這不是預先編程好的,而是一種模型自主的突發特性,并且模型也出現了自我反省和探索行為。
DeepSeek還使用了一種名為GRPO(組相對策略優化)的新優化方法,有效減少了內存使用。GRPO由DeepSeek于2024年2月發明。這也是為什么家用設備也能完整運行R1的原因。
基于此,有網友指出,鑒于Deepseek仍在使用GRPO等GPU性能較差的方法,可以推斷出,該公司可能沒有很多功能強大的Hopper GPU。這意味著,算力訓練成本也是極低的。
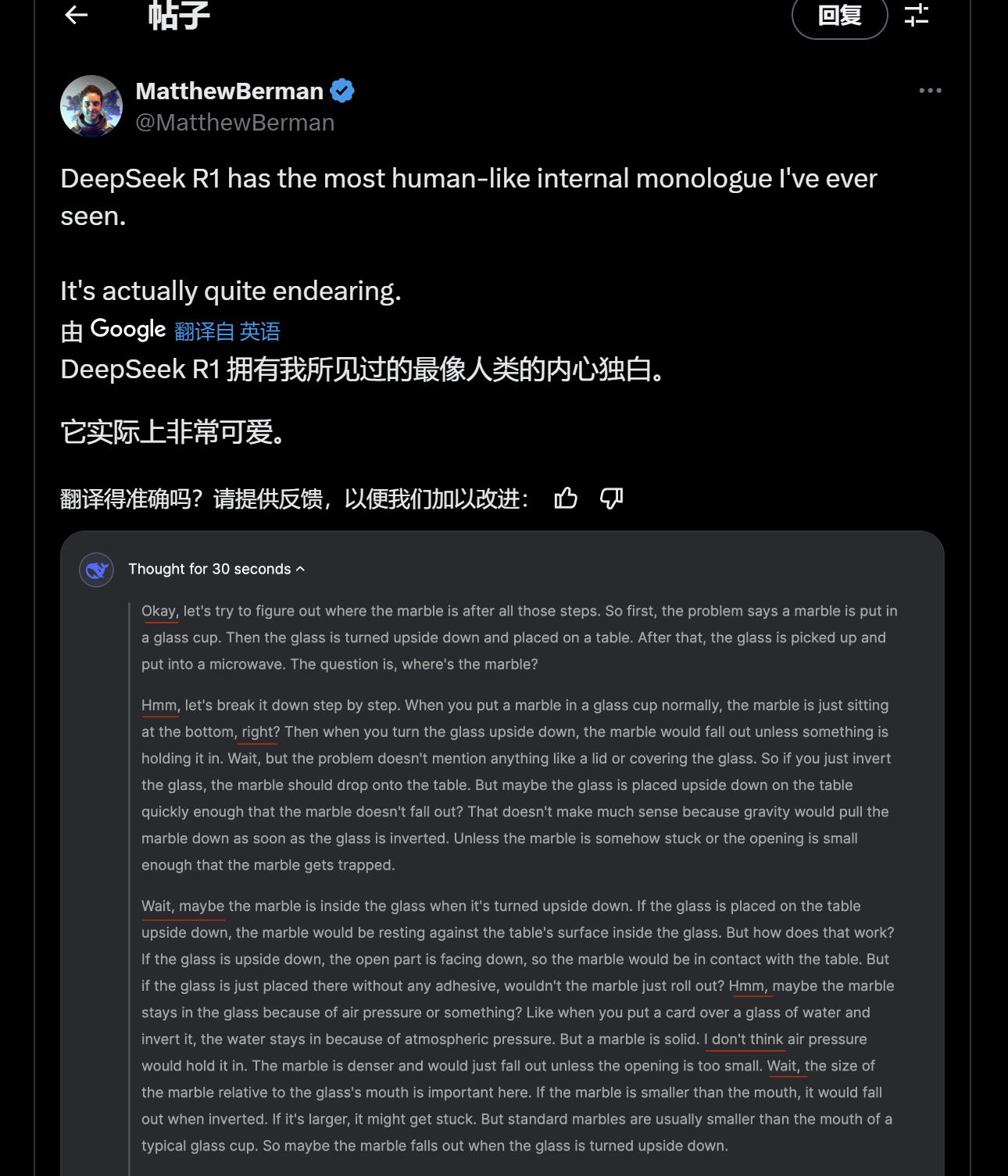
有網友評價,這是AI的“頓悟時刻”:“R1-Zero(注:R1是R1-Zero調整后的模型)證明模型可以自我開發推理策略。舉個例子:當遇到問題時,它學會了回溯并質疑其最初的假設——這是一種從未明確編程的行為。”這代表著DeepSeek的新模型已經能夠具有像人類一樣的自主學習能力了。
知名AI評測員Matthew Berman表示,R1擁有他所見過的最像人類的內心獨白。
圖片來源:X
然而,R1依然面臨著開源模型V3一樣的毛病。有網友向他提問誰訓練你的時,它回答道:“我是被OpenAI開發的”。

圖片來源:X
如需轉載請與《每日經濟新聞》報社聯系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯系索取稿酬。如您不希望作品出現在本站,可聯系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP














