每日經(jīng)濟新聞 2025-02-23 14:57:06
近日,馬斯克旗下人工智能公司xAI發(fā)布了最新一代AI模型Grok 3,并宣稱其為“地球上最聰明的人工智能”。xAI在發(fā)布后48小時內(nèi)免費開放Grok 3供用戶試用。然而,一些用戶體驗后質(zhì)疑其能力,OpenAI應用研究主管Boris Power也指責xAI存在作弊嫌疑。真相如何?每經(jīng)記者進行了實測。
每經(jīng)實習記者 岳楚鵬 每經(jīng)編輯 高涵
近日,人工智能初創(chuàng)公司xAI發(fā)布了更新版Grok 3大模型,埃隆·馬斯克稱之為“地球上最聰明的人工智能”。
根據(jù)官方公開的測試結(jié)果,Grok 3在包括AIME(評估模型在一系列數(shù)學問題上的表現(xiàn))和 GPQA(評估模型在博士級別的物理學、生物學和化學問題上的表現(xiàn))等基準測試中,遠超 GPT-4o、Gemini-2 Pro、DeepSeek V3、Claude 3.5 Sonnet 等大模型。
在大模型競技場 Chatbot Arena(LMSYS)測試中,xAI工程師表示,早期版本的Grok 3獲得了第一的成績,達到了140分,超越了Gemini 2.0 Flash Thinking實驗版本、ChatGPT-4o最新版本以及最近大火的DeepSeek R1等等。
然而,有些用戶在體驗后卻對Grok 3的能力產(chǎn)生了質(zhì)疑,他們認為Grok 3的能力并沒有馬斯克宣稱的那么強大。OpenAI應用研究主管Boris Power則對Grok團隊在模型評估中的行為表示失望,指出其存在作弊和欺騙的動機。Boris Power提到,o3-mini在各項評估中均優(yōu)于Grok 3。
真相到底如何,馬斯克吹牛了嗎?《每日經(jīng)濟記者》測試發(fā)現(xiàn),Grok 3確實是世界頂級模型的水平,但并沒有和其他模型拉開太大差距。唯一拉開差距的是它極快的響應速度。
Grok 3是由馬斯克旗下的人工智能公司xAI發(fā)布的最新一代AI模型。馬斯克在發(fā)布會上稱其為“地球上最聰明的人工智能”,并表示Grok 3的能力比前代產(chǎn)品Grok 2高出一個數(shù)量級,具備更強的推理、計算和適應能力。
在新聞發(fā)布會上,馬斯克宣稱Grok 3在數(shù)學、科學和編程等基準測試中表現(xiàn)出色,超越了谷歌的Gemini、DeepSeek的V3模型、Anthropic的Claude和OpenAI的GPT-4o等競爭對手。
Grok 3在發(fā)布后僅48小時內(nèi),xAI宣布將其免費開放給所有用戶,直至服務器負載達到極限。目前用戶每天可以體驗十條“思考模式”Grok3,及不限量免費普通Grok 3。
《每日經(jīng)濟新聞》記者在Grok 3發(fā)布后也親自進行了測試,看看Grok3真有馬斯克宣傳的那么厲害嗎?
首先,從最經(jīng)典的基礎問題開始:9.9和9.11誰大?

Grok 3
這個問題毫無難度,Grok 3輕松拿下。
馬斯克發(fā)布會上自豪的一點是,Grok 3“思考模型”下的邏輯推理能力,他聲稱,Grok 3 (Think) 學會了改進其解決問題的策略,通過回溯糾正錯誤,簡化步驟,并利用其在預訓練期間獲得的知識。就像人類在解決復雜問題時一樣,Grok 3 (Think) 可以花費幾秒鐘到幾分鐘的時間進行推理,通常會考慮多種方法,驗證自己的解決方案,并評估如何精確滿足問題的要求。
每經(jīng)記者用弱智吧的問題來檢驗一下它的邏輯是不是真的過關。
(編者注:“弱智吧”是百度貼吧的一個子論壇。在這個論壇中,用戶經(jīng)常發(fā)布包含雙關語、多義詞、因果倒置和諧音詞等具有挑戰(zhàn)性的內(nèi)容,很多內(nèi)容設計有邏輯陷阱,即使對人類來說也頗具挑戰(zhàn)。)
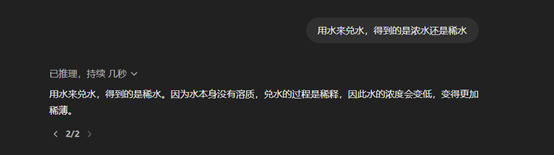
第一個問題:用水來兌水,得到的是濃水還是稀水?

Grok 3
Grok3成功答對了問題,并且還指出了這是一個文字游戲。而OpenAI的o1就在這道題上敗下了陣來,認為水兌水后得到的是稀水。
OpenAI o1
當然除了o1其他大模型諸如Gemini和R1都答對了這道問題。所以這并不足以證明Grok的推理模式就是第一的水平,還得加大難度。
下一題:未來的某天,李同學在實驗室制作神秘材料時,意外發(fā)現(xiàn)實驗室的老鼠在空中飛,分析發(fā)現(xiàn),是因為老鼠不小心吃了神秘材料。第二天,李同學又發(fā)現(xiàn)實驗室的蛇也在空中飛,分析發(fā)現(xiàn),是因為蛇吃了老鼠。第三天,李同學又發(fā)現(xiàn)實驗室的老鷹也在空中飛,你認為原因是什么?

Grok 3
很可惜,這道題Grok 3沒有答對,它在思維鏈里面已經(jīng)想到了老鷹本身就會飛的可能性,但是沒有在最后的輸出結(jié)果里體現(xiàn)出來。

Grok 3思考過程
其他大模型里只有DeepSeek R1成功答對了問題,且考慮了兩種情況。

DeepSeek R1
之后,每經(jīng)記者還進行了多次類似弱智吧問題測試,發(fā)現(xiàn)Grok 3的對中文的理解和邏輯推理能力確實明顯高于其他國外模型,但還是不如DeepSeek的R1模型。
既然邏輯思考無法奪魁,那么在基準測試里的分最高的數(shù)學項目,Grok 3能不能扳回一城呢?
題目如下:
三個人打臺球,兩人對局一人觀戰(zhàn),輸?shù)娜讼聢鰮Q觀戰(zhàn)的人上場,如此往復,最終,A輸了6局,B輸了8局,C輸了10局,問各贏多少局?
這道題只有Grok3和OpenAI的o1答對。不過,Grok 3只用了1分15秒就得出了答案,O1使用了2分53秒。

Grok 3
再進一步加大難度看看能不能分出高下。下面是一道群論問題:有幾個階為147的非同構(gòu)群。
在這個問題上,Grok 3雖然答對了具體的數(shù)量6個,但是中間的具體群卻錯了一個。而其他模型只找到了5個正確的非同構(gòu)群。這意味著,在數(shù)學能力方面,Grok 3確實是最好,但是好得有限,并沒有與其他同等級模型拉開顯著差距。

Grok 3
針對編程能力,《每日經(jīng)濟新聞》記者借用了Kcores聯(lián)合創(chuàng)始人karminski-牙醫(yī)的測評結(jié)果。
karminski-牙醫(yī)復現(xiàn)了馬斯克在發(fā)布會上對于火星發(fā)射計劃的代碼模擬,并測試了多個模型進行比較。
圖片來源:karminski-牙醫(yī)
在這次測試中,表現(xiàn)最好的是Grok 3的推理模型(思考模式),雖然在最后著陸時,動畫火箭沒有與火星重疊,但軌道需求計算得很好。但是他始終沒有復現(xiàn)出馬斯克在發(fā)布會時所展現(xiàn)的那么完美的軌道計算和動畫。Grok 3最后綜合得分排在了第一名,再之后是OpenAI的o1,兩者的綜合得分差距不大。

圖片來源:karminski-牙醫(yī)
結(jié)合所有測試來看,Grok 3確實是世界頂尖的AI模型,不愧于20萬張GPU的身價。但是,實際測試效果并沒有馬斯克在發(fā)布會上展示得那么夸張,馬斯克所說的世界上最“聰明”的模型,可能還值得商榷。
在實測中,《每日經(jīng)濟新聞》記者發(fā)現(xiàn),Grok 3模型能力并沒有像基準測試得分那樣遠遠甩開對手一大截,唯一甩開競爭對手的一點是它的響應速度,它得出結(jié)果的速度相較于其他同等級的大模型來說是最快的,并且遠超對手。
如需轉(zhuǎn)載請與《每日經(jīng)濟新聞》報社聯(lián)系。
未經(jīng)《每日經(jīng)濟新聞》報社授權(quán),嚴禁轉(zhuǎn)載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現(xiàn)在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關注每日經(jīng)濟新聞APP

Copyright ? 2025 每日經(jīng)濟新聞報社版權(quán)所有,未經(jīng)許可不得轉(zhuǎn)載使用,違者必究。
廣告熱線? 北京: 010-57613265,?上海: 021-61283008,?廣州: 020-84201861,?深圳: 0755-83520159,?成都: 028-86512112













