每日經濟新聞 2025-03-06 16:33:47
每經編輯 孫志成
3月6日,阿里通義千問大模型團隊宣布,正式推出最新的推理模型QwQ-32B。
阿里巴巴稱,這是一款擁有320億參數的模型,其性能可與具備6710億參數(其中370億被激活)的DeepSeek-R1媲美,但二者在參數量上相差將近20倍。
據介紹,通過大規(guī)模強化學習,千問QwQ-32B在數學、代碼及通用能力上實現質的飛躍,整體性能比肩DeepSeek-R1,同時大幅降低了部署使用成本,在消費級顯卡上也能實現本地部署。
在數學推理、編程能力和通用能力的一系列基準測試中,通義千問大模型團隊將QwQ-32B與OpenAI的o1-mini以及DeepSeek滿血版及蒸餾版進行了比較,結果顯示,在測試數學能力的AIME24評測集上,以及評估代碼能力的LiveCodeBench中,QwQ-32B表現與DeepSeek-R1相當,遠勝于o1-mini及相同尺寸的R1蒸餾模型。
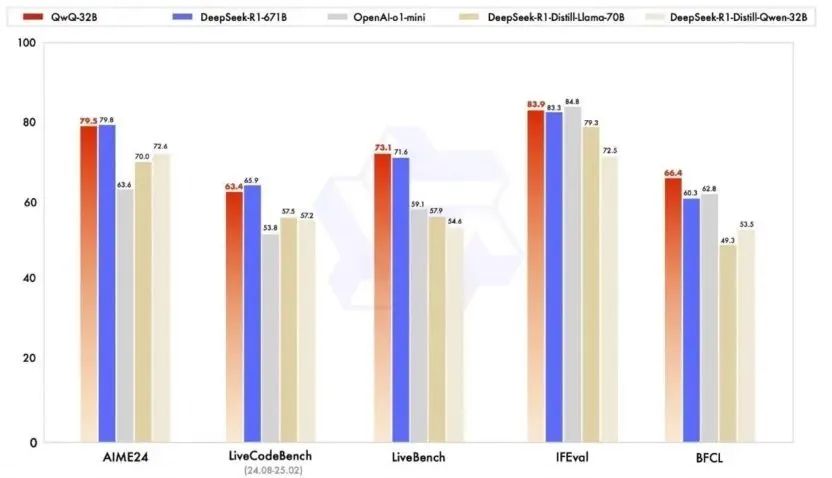
據介紹,在冷啟動基礎上,阿里通義團隊針對數學和編程任務、通用能力分別進行了兩輪大規(guī)模強化學習。在初始階段,特別針對數學和編程任務進行了強化學習訓練。與依賴傳統(tǒng)的獎勵模型不同,通義千問大模型團隊通過校驗生成答案的正確性來為數學問題提供反饋,并通過代碼執(zhí)行服務器評估生成的代碼是否成功通過測試用例來提供代碼的反饋。
業(yè)內人士分析,QwQ-32B的成功表明,將強大的基礎模型與大規(guī)模強化學習相結合,能夠在較小的參數規(guī)模下實現卓越性能,這為未來通向通用人工智能提供了可行路徑。
值得注意的是,盡管DeepSeek-R1擁有6710億的巨型參數量,但由于DeepSeek創(chuàng)新性地使用了MoE(混合專家模型)架構以及MLA(多頭潛在注意力機制)的方法,每次推理僅激活370億參數(占總量的5.5%)。這使得DeepSeek-R1雖然整體很大,但實際干活時只需要動用一小部分力量,能夠做到節(jié)省資源,高效完成任務。
阿里通義團隊表示,未來將繼續(xù)探索將智能體與強化學習的集成,以實現長時推理,探索更高智能進而最終實現AGI的目標。
目前,阿里已采用寬松的Apache2.0協(xié)議,將QwQ-32B模型向全球開源,所有人都可免費下載及商用,也可以通過阿里云百煉平臺直接調用模型API服務。同時,用戶也可通過通義APP免費體驗最新的QwQ-32B模型。
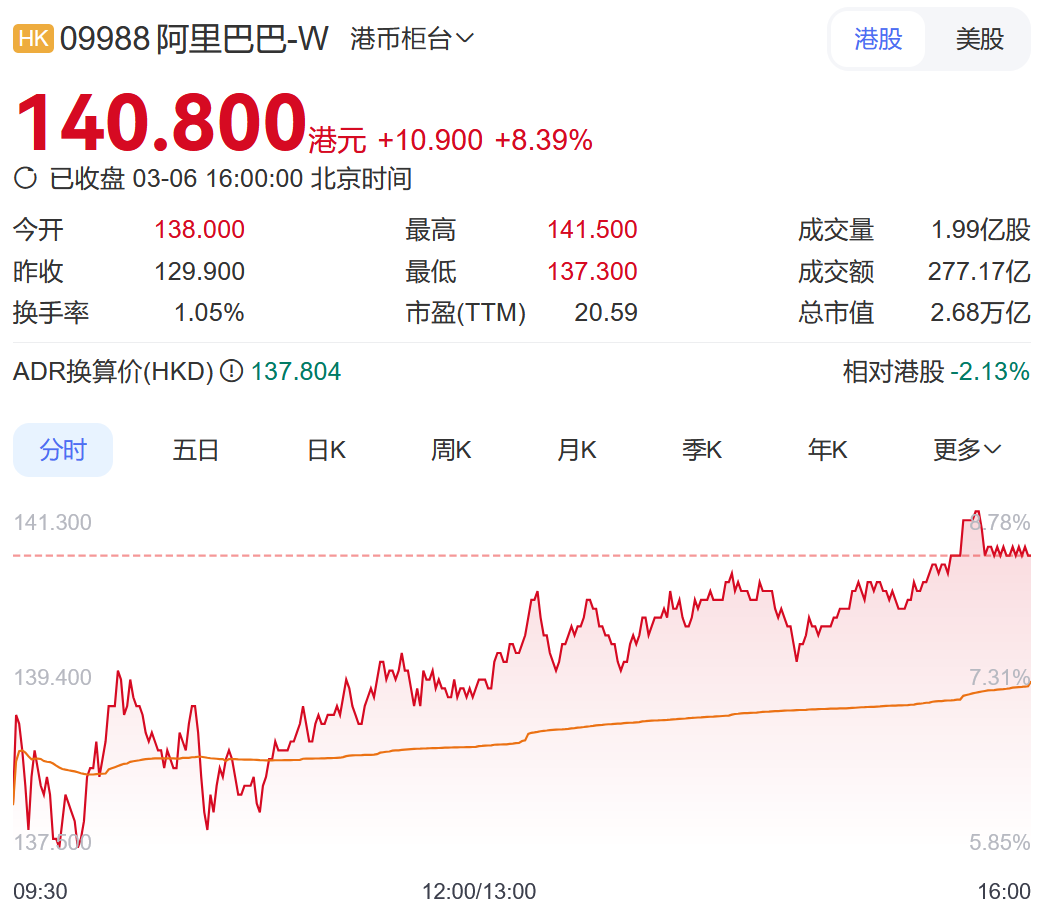
3月6日早盤,阿里巴巴集團(09988.HK)港股大幅高開漲超6%,截至收盤漲超8%。
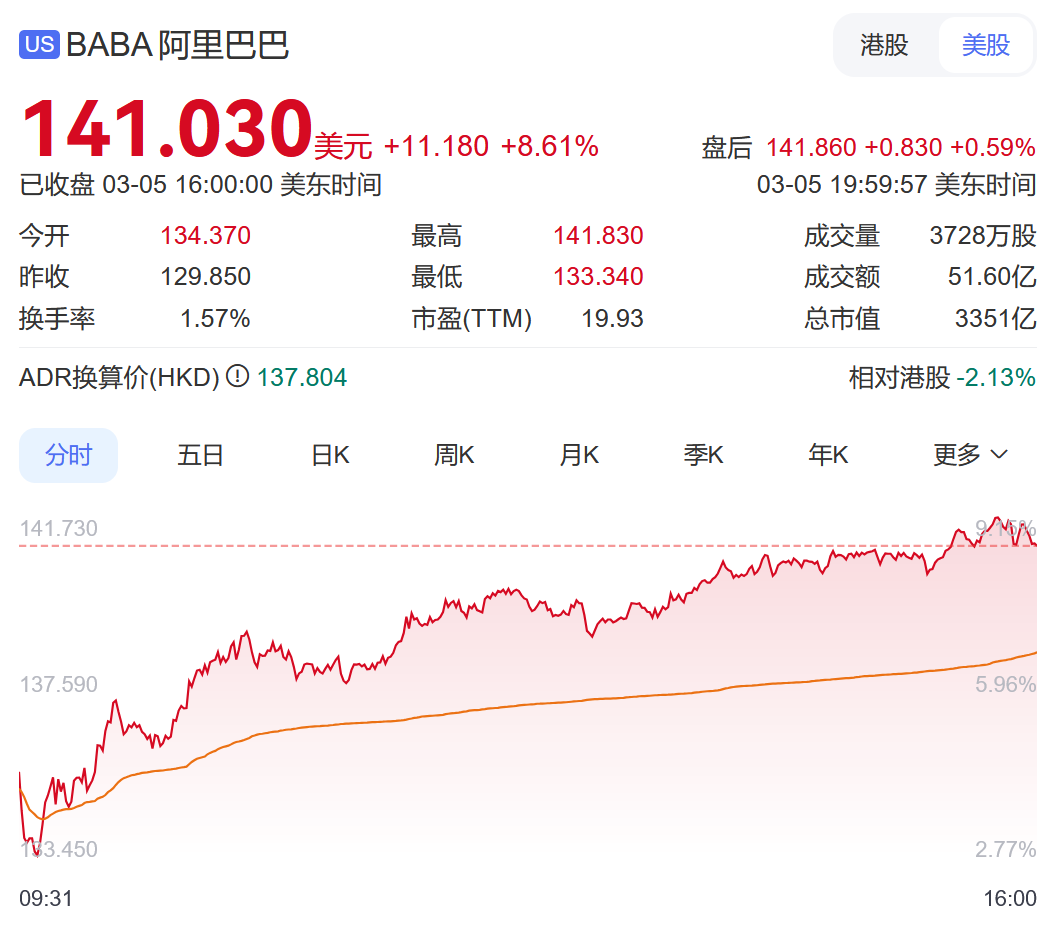
3月5日晚,阿里巴巴美股大漲超8%。
此前,2月25日,阿里通義Qwen發(fā)布基于旗艦模型Qwen2.5-Max構建的推理模型QwQ-Max-Preview預覽版,支持聯(lián)網搜索,會和DeepSeek以及Kimi的推理模型一樣展現思考過程.
長江證券研報指出,近期,阿里在AI領域持續(xù)發(fā)力,踐行了其AI驅動戰(zhàn)略,隨著其后續(xù)投入的逐步提升,相關成果有望加速迭代,相關成果或將惠及相關產業(yè)鏈,加速AI應用落地,進而進一步帶動算力需求的爆發(fā)。同時,隨著阿里在AI基礎設施、基礎模型平臺及AI原生應用、現有業(yè)務的AI轉型等三方面加大投入,或將引領中國AI產業(yè)加速發(fā)展。
編輯|||孫志成 杜恒峰
校對|何小桃
封面圖自每經記者 張涵 攝
每日經濟新聞綜合自證券時報、公開資料等
如需轉載請與《每日經濟新聞》報社聯(lián)系。
未經《每日經濟新聞》報社授權,嚴禁轉載或鏡像,違者必究。
讀者熱線:4008890008
特別提醒:如果我們使用了您的圖片,請作者與本站聯(lián)系索取稿酬。如您不希望作品出現在本站,可聯(lián)系我們要求撤下您的作品。
歡迎關注每日經濟新聞APP













